

Introduction to Elasticsearch
|
您目前处于:Development
2016-10-04
|
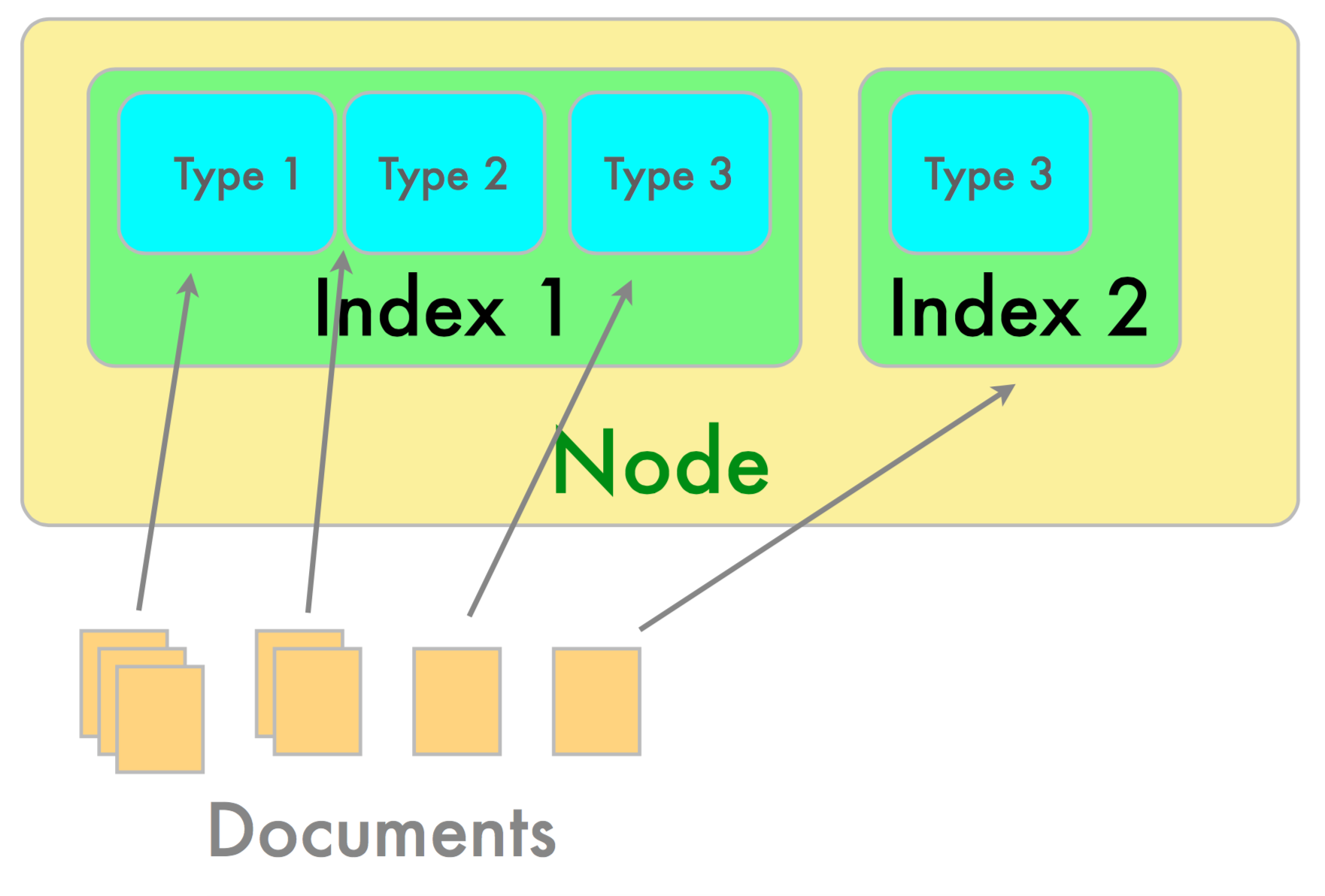
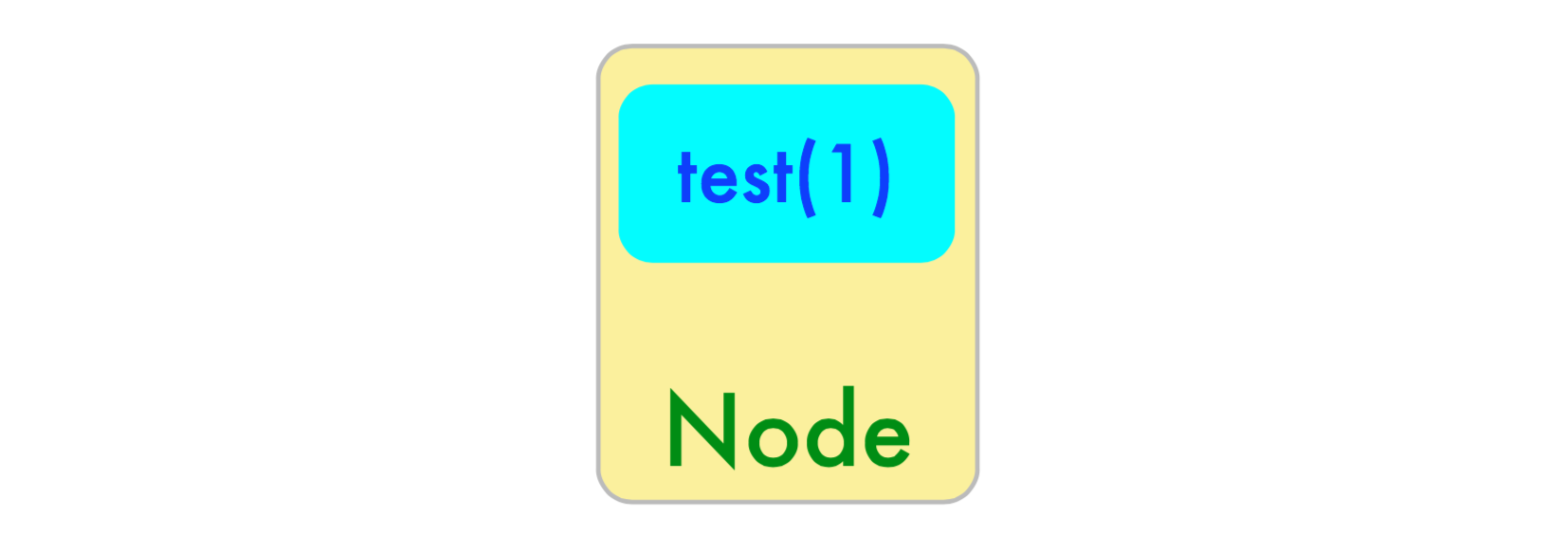
系列文章:• Introduction to Elasticsearch • Getting Started with ElasticSearch What is Elasticsearch? Elasticsearch is an open-source, distributed, real-time, document indexer with support for online analytics Features at a Glance Extremely elegant and powerful REST API • Almost all search engine features are accessible over plain HTTP • JSON formatted queries and results • Can test/experiment/debug with simple tools like curl Schema-Less Data Model • Allows great flexibility for application designer • Can index arbitrary documents right away with no schema metadata • Can also tweak type/field mappings for indexes as needed Fully Distributed and Highly-Available • Tunable index-level write-path (index) and read-path (query) distribution policies • P2P node operations with recoverable master node, multicast auto-discovery (configurable) • Plays well in VM/Cloud provisioned environments • Indexes scale horizontally as new nodes are added • Search Cluster performs automatic failover and recovery Advanced Search Features • Full-Text search, autocomplete, facets, real-time search analytics • Powerful Query DSL • Multi-Language Support • Built-in Tokenizers,Filters and Analyzers for most common search needs Concepts Clusters/Nodes: ES is a deployed as a cluster of individual nodes with a single master node. Each node can have many indexes hosted on it. Documents: In ES you index documents. Document indexing is a distributed atomic operation with versioning support and transaction logs. Every document is associated with an index and has at least a type and an id. Indexes: Similar to a database in traditional relational stores. Indexes are a logical namespace and have a primary shard and zero or more replica shards in the cluster. A single index has mappings which may define several types stored in the index. Indexes store a mapping between terms and documents. Mappings: Mappings are like schemas in relational database. Mappings define a type within an index along with some index-wide settings. Unlike a traditional database, in ES types do not have to be explicitly defined ahead of time. Indexes can be created without explicit mappings at all in which case ES infer a mapping from the source documents being indexed. Types: Types are like tables in a database. A type defines fields along with optional information about how that field should be indexed. If a request is made to index a document with fields that don’t have explicit type information ES will attempt to guess an appropriate type based on the indexed data. Queries: A query is a request to retrieve matching documents (“hits”) from one or more indexes. ES can query for exact term matches or more sophisticated full text searches across several fields or indexes at once. The query options are also quite powerful and support things like sorting, filtering, aggregate statistics, facet counts and much more. Analysis: Analysis is the process of converting unstructured text into terms. It includes things like ignoring punctuation, common stop words (‘the’,’a’,‘on’,‘and’), performing case normalizing, breaking a work into ngrams (smaller pieces based on substrings), etc. to support full-text search. Is ES analysis happens at index-time and query-time. Index Layout
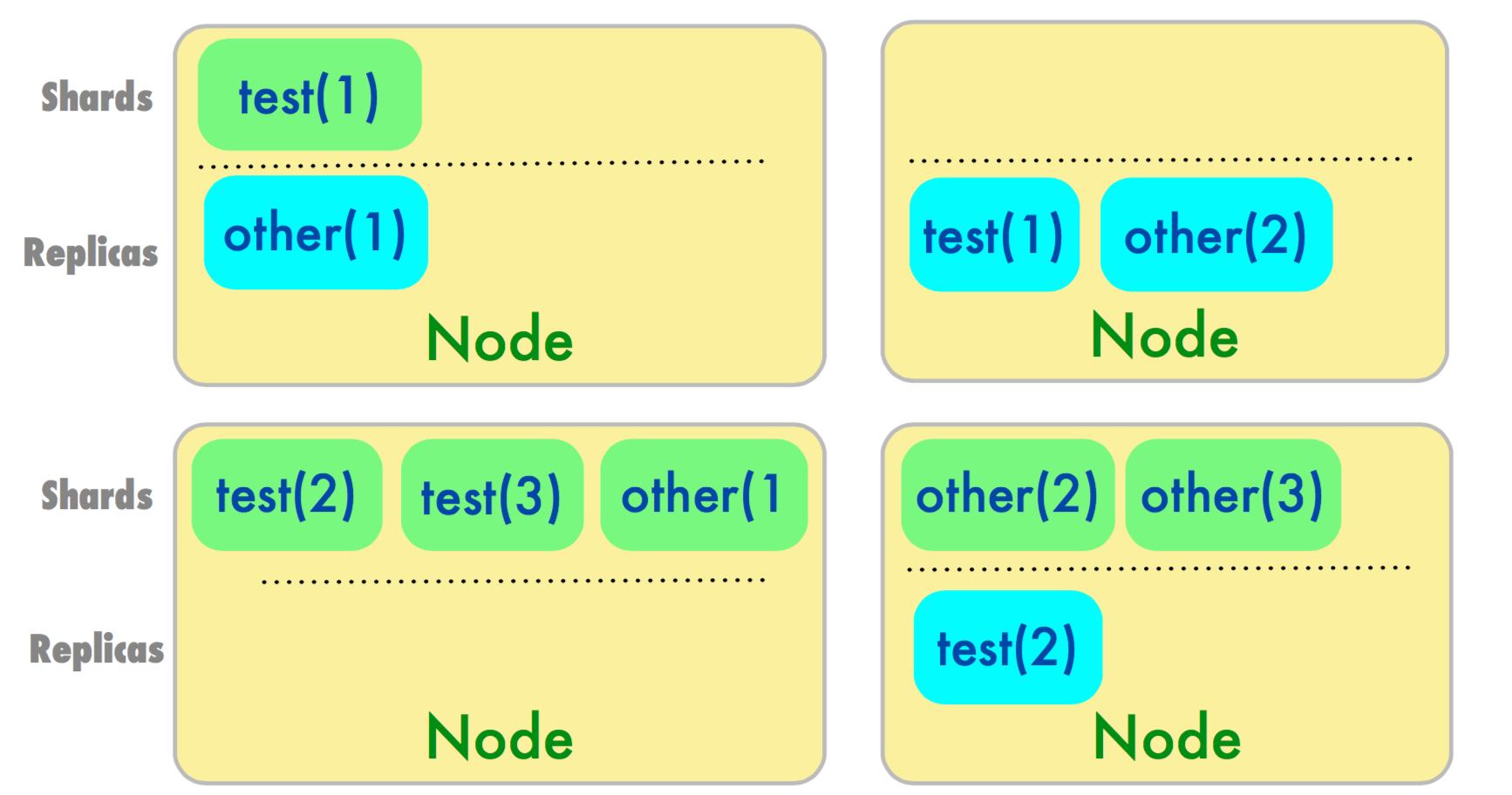
Shards and Replicas curl -XPUT localhost:9200/test -d ‘{
“settings”: {
“number_of_shards”: 1,
“number_of_replicas”: 0 }
}’
curl -XPUT localhost:9200/test -d ‘{
“settings”: {
“number_of_shards”: 3,
“number_of_replicas”: 2}
}’
Shard Placement
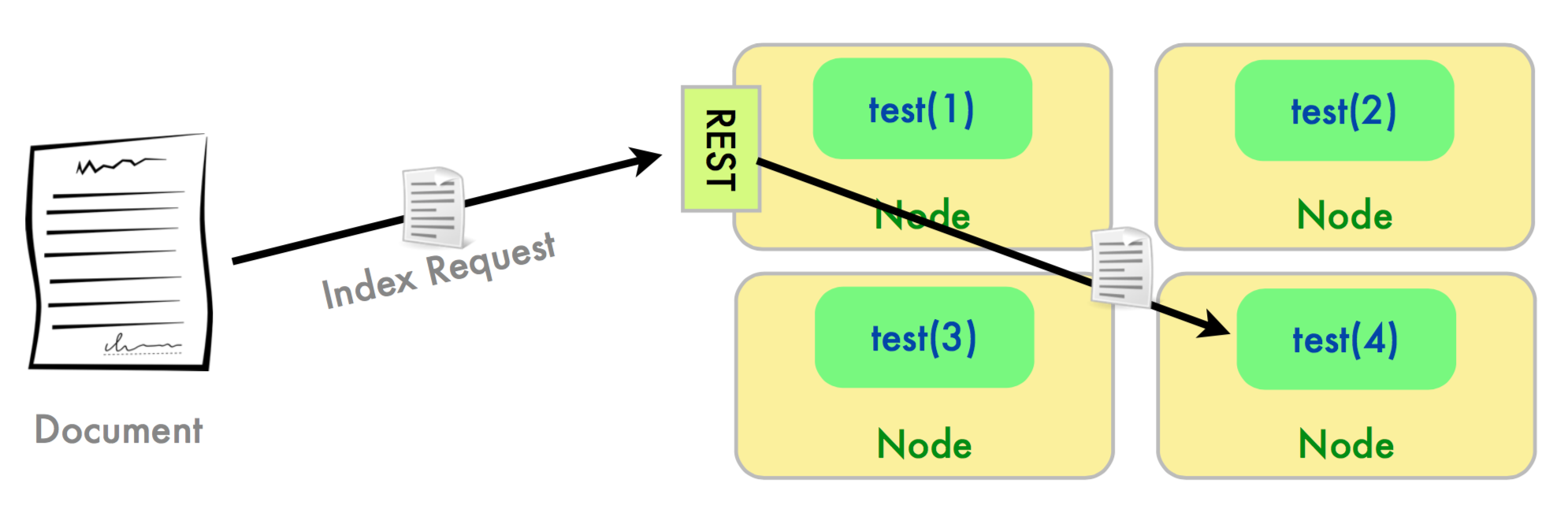
By default shards in ES are placed onto nodes by taking the the hash of the document id modulo #shards for the destination index.
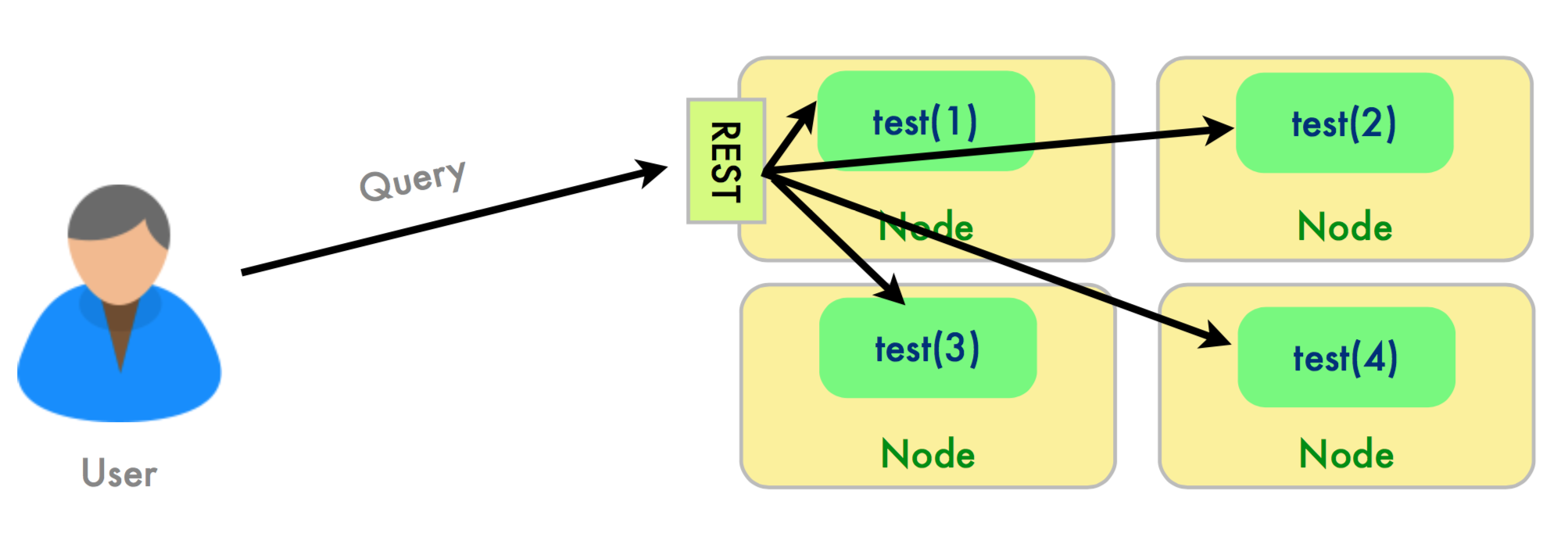
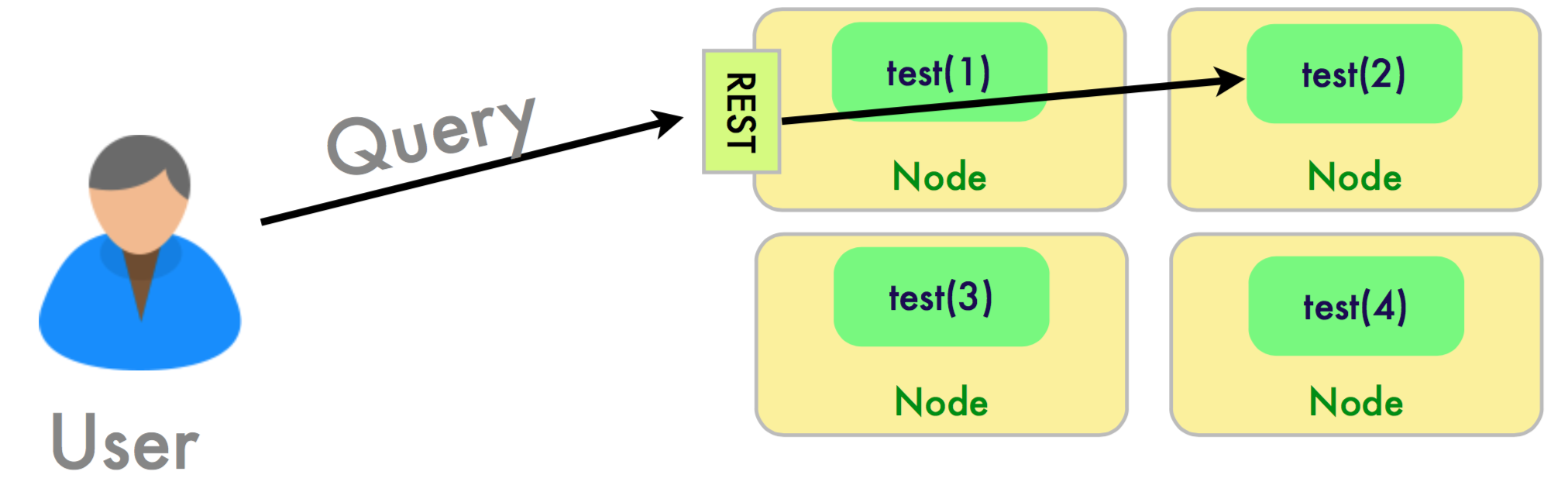
Querying is more complex. Generally potential search hits are spread across all the shards for that index so the query is distributed to all shards and the results are combined somehow before being returned (scatter/ gather architecture). Routing url -XGET 'localhost:9200/test/product/_query?routing=electronics'
Routing can be used to control which shards (and therefore which nodes) receive requests to search for a document. When routing is enabled the user can specify a value at either index time or query time to determine which shards are used for indexing/querying. The same routing value is always routed to the same shard for a given index. ES Document Model • Documents first broken down into terms to create inverted index back to original source (more on this later) • Document content is up to you and can be: ✴ unstructured (articles/tweets) ✴ semi-structured (log entries/emails) ✴ structured (patient records/emplyee records) or any combination thereof • Queries can look for exact term matches (e.g. productCategory == entertainment) or “best match” based on scoring each document against search criteria • All documents in ES have an associated index, type and id. Analyzers • In ES Analysis is the process of breaking down raw document text into terms that will be indexed in a single lucene index. • The role of analysis is performed by Analyzers. Analyzers themselves are broken into logical parts: ✴ CharFilter: An optional component that directly modifies the underlying char stream for example to remove HTML tags or convert characters ✴ Tokenizer: Component that extracts multiple terms from a single text string ✴ TokenFilters: Component that modifies, adds or removes tokens for example to convert all characters to uppercase or remove common stopwords • Can be index-specific or shared globally. • ES ships with several common analyzers. You can also create a custom analyzers with a single logical name by specifying the CharFilter, Tokenizer and TokenFilters that comprise it. Indexing a Document
• This will index all the fields of our document in the index named test with a type mapping of product an an id of 1 • Notice that we did not create any indexes ahead of time or define any information about the schema of the document we just indexed! • ES returns a response JSON object acknowledging our operation
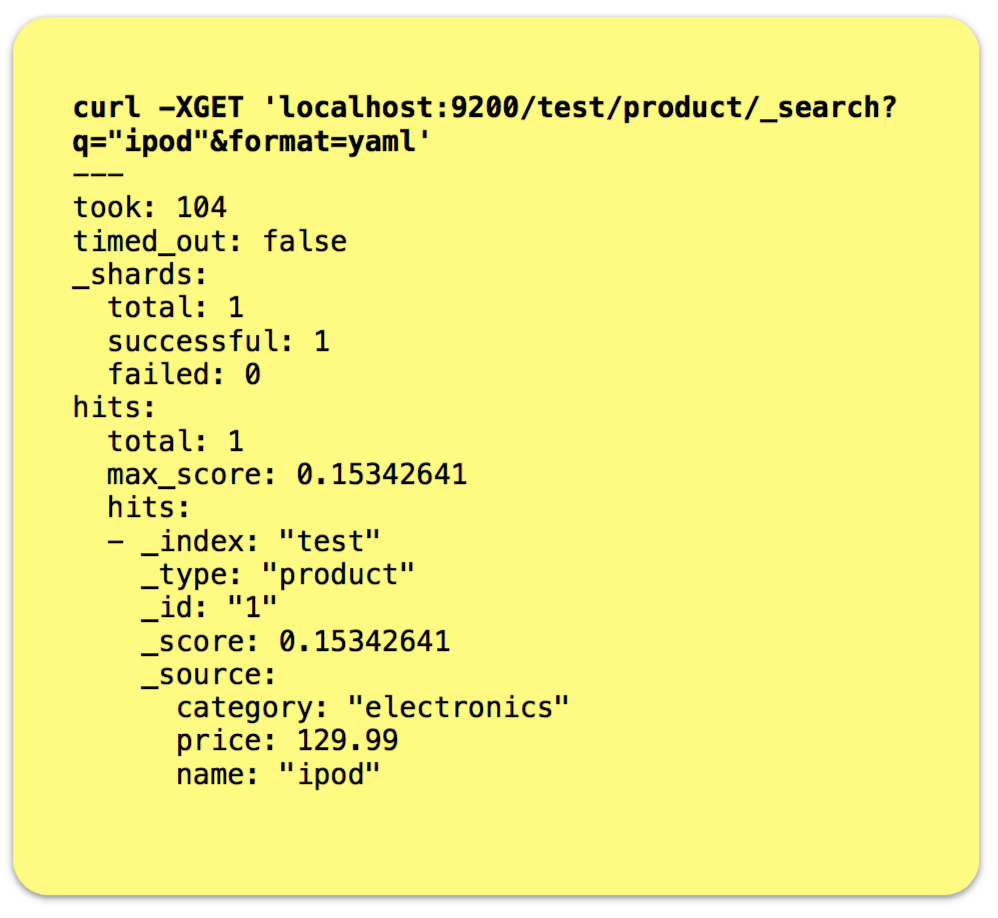
• Using POST method this time instead of PUT • No explicit id provided to ES so it auto-generates one for us. Id is returned in the id field of the JSON response. • Notice the _version field in the response. ES keeps a version number for every indexed document. The same document can be updated or re-indexed with different attributes and the version will be automatically incremented by ES. Introspecting Indexes • The mapping API lets us see how ES mapped our document fields • ES determined that the price field was of type double based on the first document indexed • Using the ‘format=yaml’ parameter in API Get requests formats the response as YAML which is sometimes easier to read than JSON (the default)
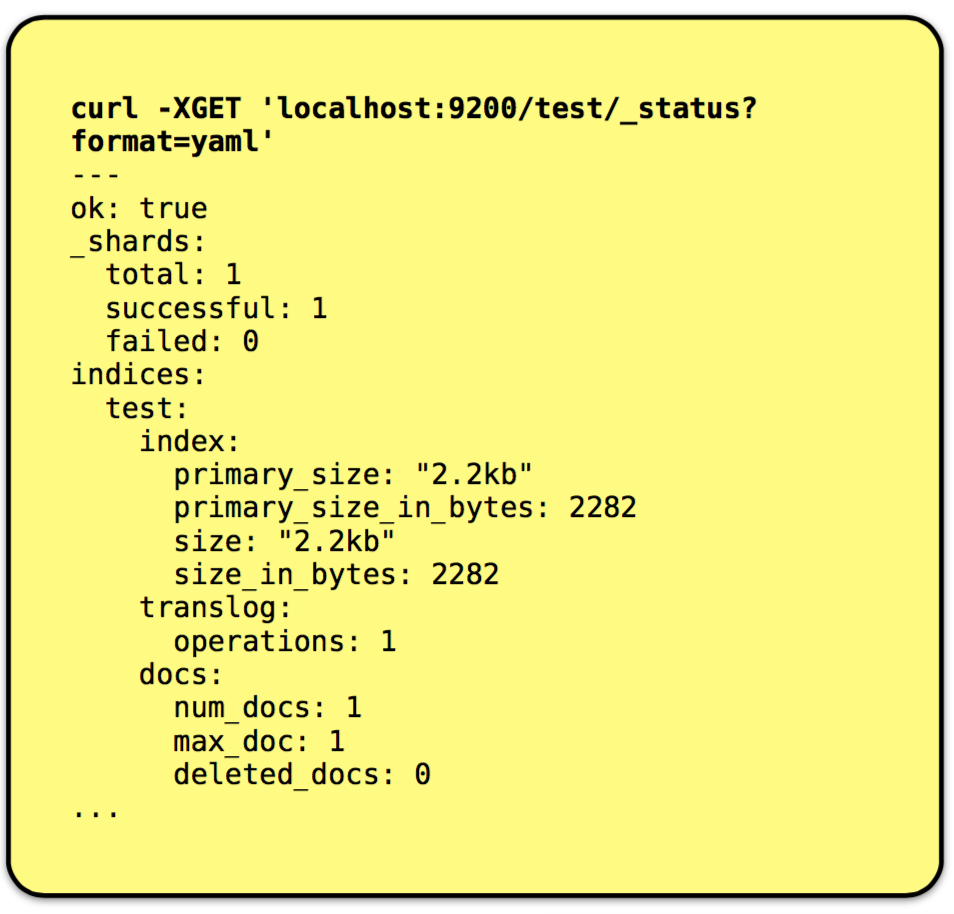
• The _status path lets us examine lots of interesting facts about an index. • Here we see that a new index ‘test’ was created after our document PUT call and that it is 2.2KB in size and contains a single document
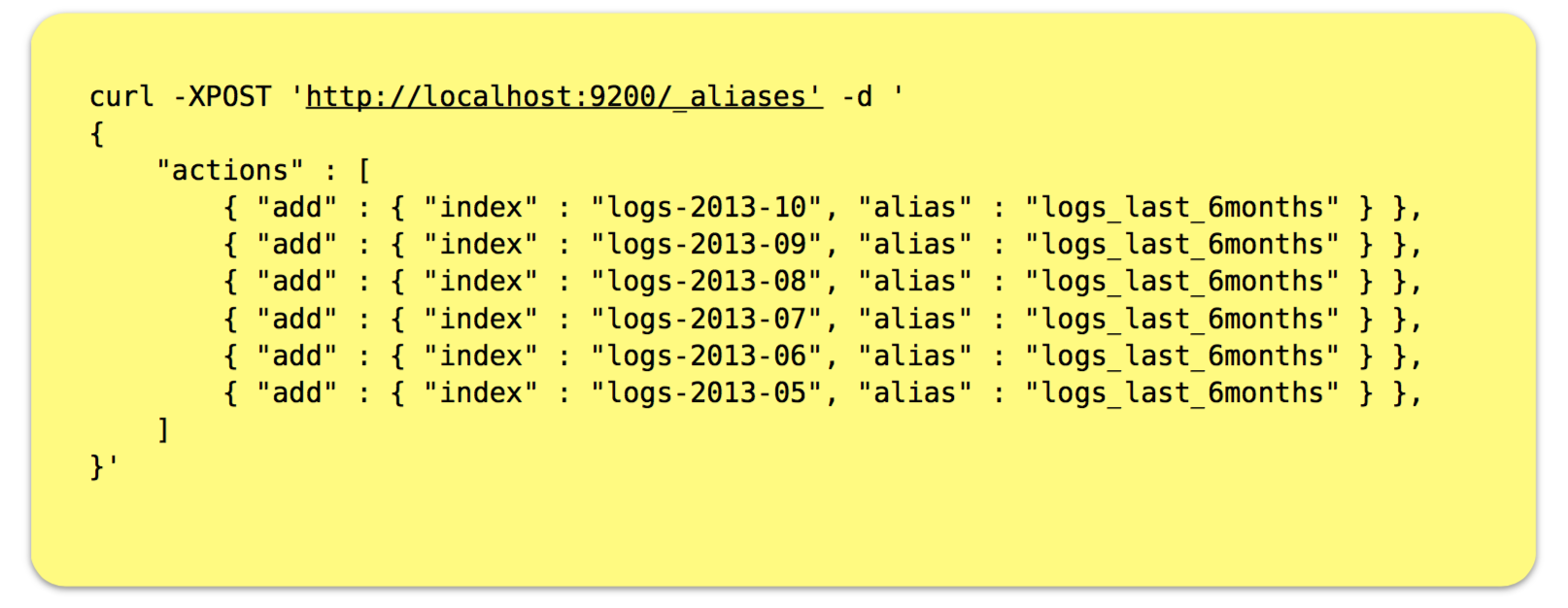
Index Design: Date Bounded Indexes • A very common pattern for user-generated data (e.g. tweets/emails) and machine generated data (log events,system metrics) is to segregate data by date or timestamp. • ES makes it easy to create a separate index at whatever interval makes sense for your application (daily/weekly/monthly). For example if we are indexing log data by day our indexes might look like: logs-2013-10-01 logs-2013-10-02 logs-2013-10-03 • Now we can query for all the logs in October and November 2013 with the following URI form: http://localhost:9200/logs-2013-10*,logs-2013-11*/ Index Aliases
• Index aliases allow us to manage one or more individual indexes under a single logical name. • This is perfect for things like creating an index alias to hold a sliding window of indexes or providing a filtered “view” on a subset of an indexes actual data. • Like other aspects of ES, a REST API is exposed that allows complete programmatic management of aliases Retrieving Documents
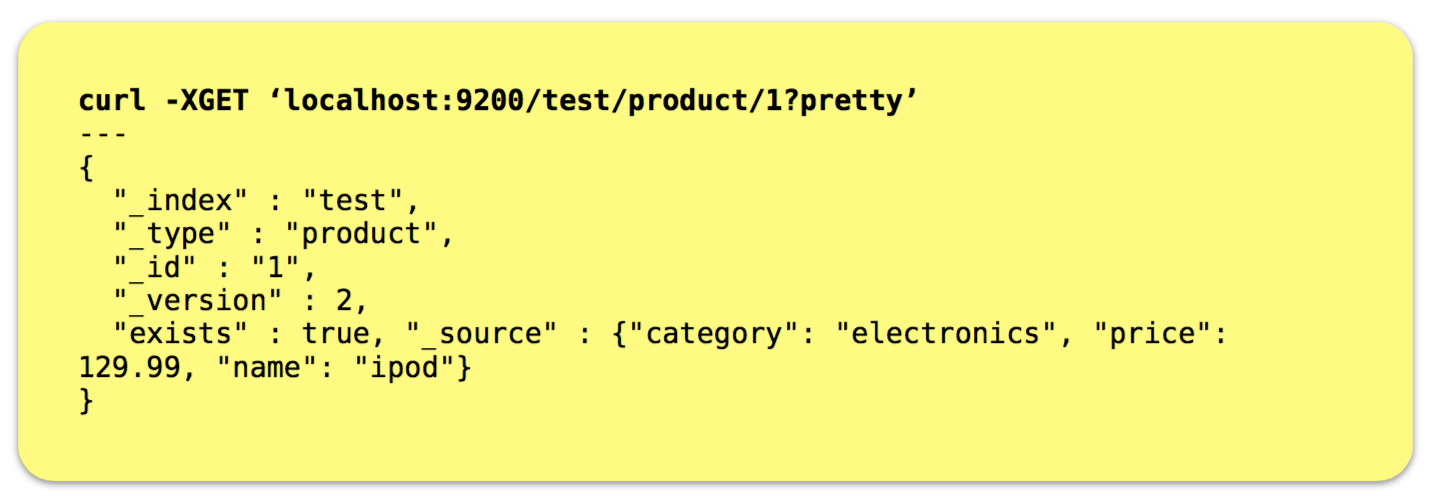
The primary purpose for setting up an ES cluster is to support full-text or complex querying across documents however you can also retrieve a specific document if you happen to know its id (Similar to KV stores) Manual Index Creation • For Indexes that are created “lazily” in ES, a mapping is created “on-the-fly” from introspecting the documents being indexed. • You can specify mappings at index creation time or in a config file stored at each node.
Mappings
• Mappings can also define the underlying analyzer that is used on indexed field values. Field mappings can specify both an index analyzer and a query analyzer or opt out of analyzation completely. • A single document field can actually have multiple settings (index settings, type, etc) applied simultaneously using the multi_field type, see reference guide for a full description. Dynamic Field Mappings
• Sometimes we want to control how certain fields get mapped dynamically indexes but we don’t know every possible field ahead of time, dynamic mapping templates help with this. • A dynamic mapping template allows us to use pattern matching to control how new fields get mapped dynamically • Within the template spec {dynamic_type} is a placeholder for the type that ES automatically infers for a given field and {name} is the original name of the field in the source document Index Templates
• Index templates allow you to create templates that will automatically be applied to new indexes • Very handy when using a temporal index design strategy like ‘index per day’ or similar • Templates use a index name matching strategy to decide if they apply to a newly created index. If there is a match the contents of the template are copied into the new index settings. • Multiple templates can match a single index. Unless the order parameter is given templates are applied in the order they are defined. Performing Queries
• The _search path is the standard way to query an ES index • Using the q=<query> form performs a full- text search by parsing the query string value. While this is convenient for a some queries, ES offers a much richer query API via it’s JSON Query object and query DSL • Normally a search query also returns the _source field for every search hit which contains the document as it was originally indexed Multi-Index / Multi- Type API Conventions
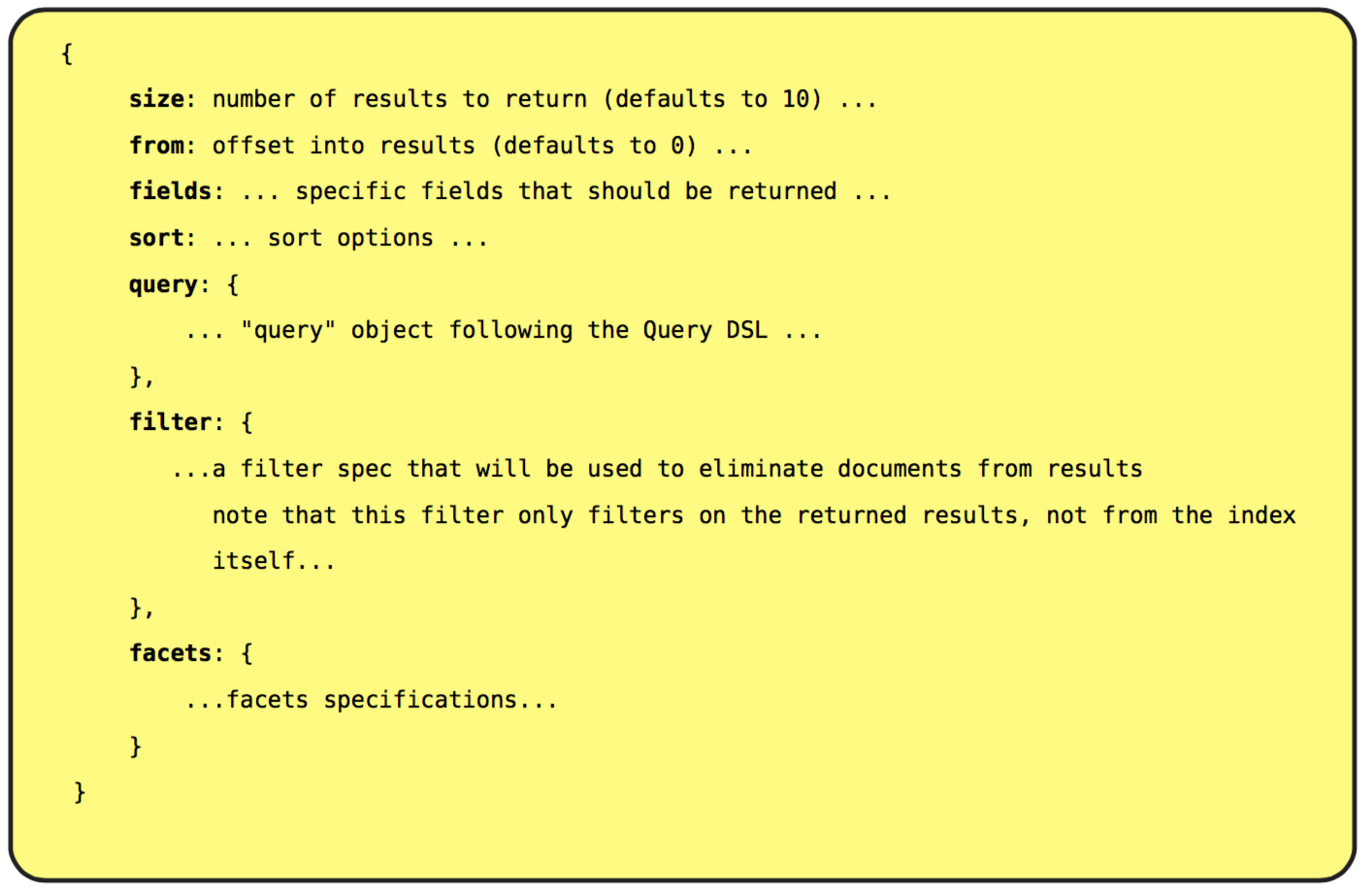
The ES Query Object • By Providing a “Query Object” (JSON Blob) to ES during a search operation, you can form very complex search queries • The size, from, and sort attributes effect how many results are returned and in what order • The query, filter, facets attributes are the used to control the content of search results • The query attribute is very customizable and has it’s own flexible DSL
Queries vs. Filters • Since both queries and filters can return similar search results, it can be confusing to know which one to use for a given search scenario • The ES Guide offers some general advice for when to use queries vs. filters: Use queries when: ✴ Full text search is needed ✴ The results of the search depend on a relevance score Use filters when: ✴ Results of search are binary (yes/no) ✴ Querying against exact values Performance Tips • Use filters instead of queries when possible. Doing so leverages underlying efficiencies and cache opportunities from Lucene. From the ES documentation: Filters are very handy since they perform an order of magnitude better than plain queries since no scoring is performed and they are automatically cached. Filters can be a great candidate for caching. Caching the result of a filter does not require a lot of memory, and will cause other queries executing against the same filter (same parameters) to be blazingly fast. • Don’t store implicit fields unless they are needed. _source This field stores the entire source document by default, if you don’t need this not storing saves significant storage space _all This field stores all stored fields in a single field by default, if you don’t need to search for values in all fields for a given index and type you can leave it off. Security Considerations • Default access to ES, including its management APIs, is over unauthorized/unauthenticated REST-based APIs over plain HTTP. Can be used for various tasks, such as dropping the index or modifying the index definition to store more data. • In a production setting you should ensure: ✴ ES in only accessible from behind a firewall, don’t expose HTTP endpoints outside of a firewall! ✴ Set http.enabled = false to disable Netty and HTTP access on nodes that do not need to expose it. Alternatively, can use the ES Jetty plugin (https://github.com/sonian/ elasticsearch-jetty) to implement authentication and encryption. • If you have more stringent security requirements consider the following: ✴ By default ES uses multicast auto-discovery with an auto-join capability for new nodes. Use unicast whitelisting instead to ensure that new “rogue” nodes can’t be started nefariously. ✴ The lucene index data is stored on the node-local filesystem by default in unencrypted files. At a minimum, set proper file system access controls to prevent unauthorized access. You may also want to consider using an encrypted filesystem for your data directories to protect the data while it is stored. Cluster Load Balancing •ES nodes can have up to three roles: ✴Master - Master nodes are eligible for being declared the master for the whole cluster. Master nodes act as coordinators for the entire cluster. Only a single master is active at one time and if it fails a new one is automatically selected from the master election pool ✴Data Nodes - Data nodes hold the lucene index shards that make up ES distributed indexes ✴Client Nodes - Client nodes handle incoming client REST requests and coordinate data to satisfy them from the cluster’s data nodes •The default mode of operation for ES is to have each node take on all 3 roles within the cluster but you can tweak this in elasticsearch.yml and opt out of being a master or data node. Plugins • Plugins extend the core ES capability and provide extended or optional functionality. • Plugins can also have a “site” associated with them. This allows plugin writers to create third-party web- based UIs for interacting with their plugins • Some common plugins provide additional transport capabilities or integrations with other data technologies like NoSQL databases, relational databases, JMS, etc. Reference: http://www.slideshare.net/omnisis/intro-to-elasticsearch 转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |









4712
阅读数


视频课程

好文推荐