

Elasticsearch from the bottom up
|
您目前处于:Development
2016-04-13
|
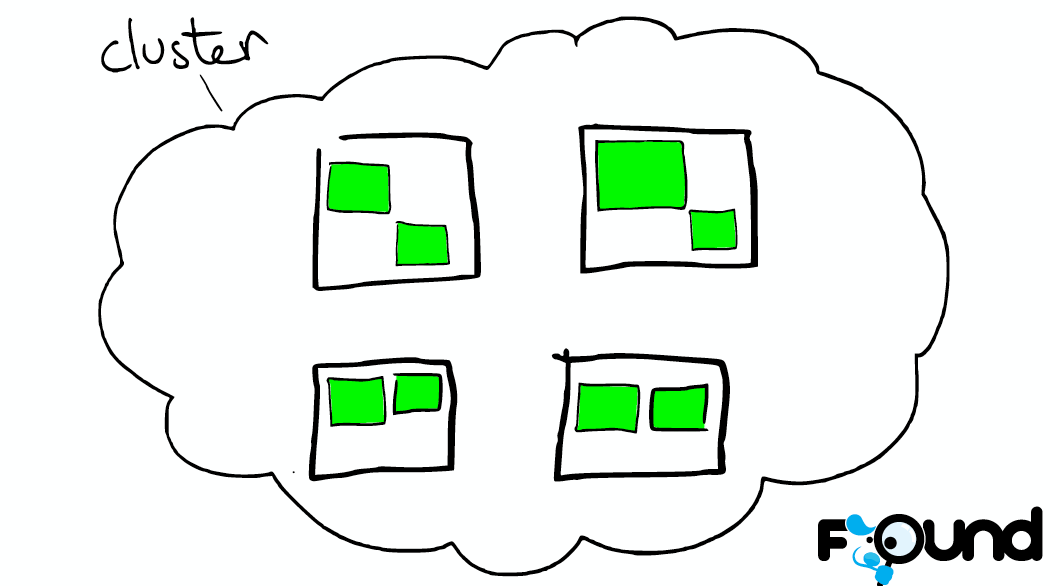
系列文章:• Customizing Your Document Routing • Elasticsearch from the bottom up Elasticsearch is a highly scalable open-source full-text search and analytics engine. It allows you to store, search, and analyze big volumes of data quickly and in near real time. There are a few concepts that are core to Elasticsearch. Near Realtime (NRT) Elasticsearch is a near real time search platform. What this means is there is a slight latency (normally one second) from the time you index a document until the time it becomes searchable. Cluster A cluster is a collection of one or more nodes [一 个cluster可以包含一个或多个node ] (servers) that together holds your entire data and provides federated indexing and search capabilities across all nodes. A cluster is identified by a unique name which by default is "elasticsearch". This name is important because a node can only be part of a cluster if the node is set up to join the cluster by its name.
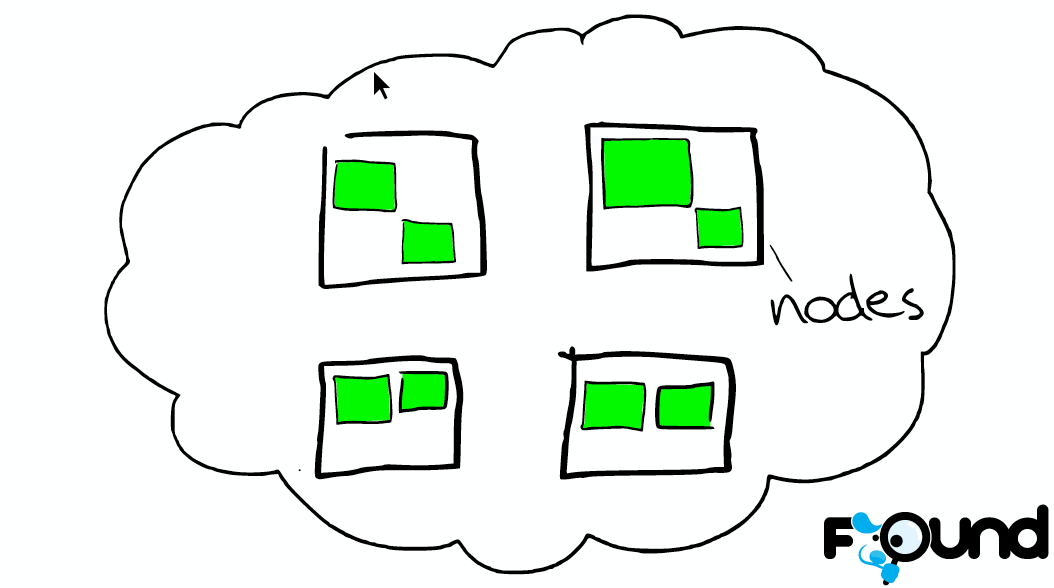
Node A node is a single server [node是cluster中的一个节点] that is part of your cluster, stores your data, and participates in the cluster’s indexing and search capabilities. In a single cluster, you can have as many nodes as you want.
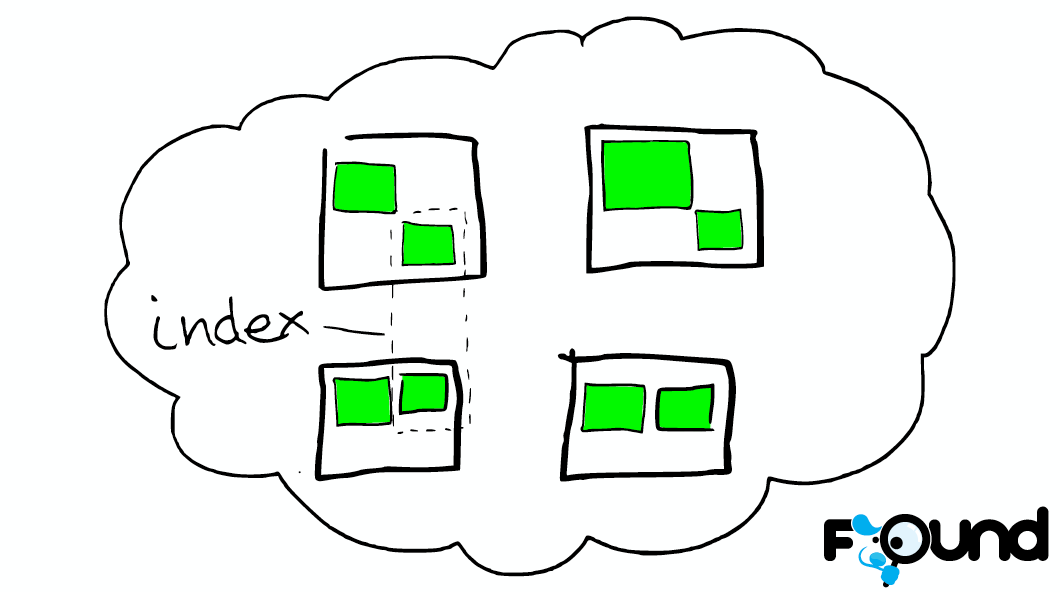
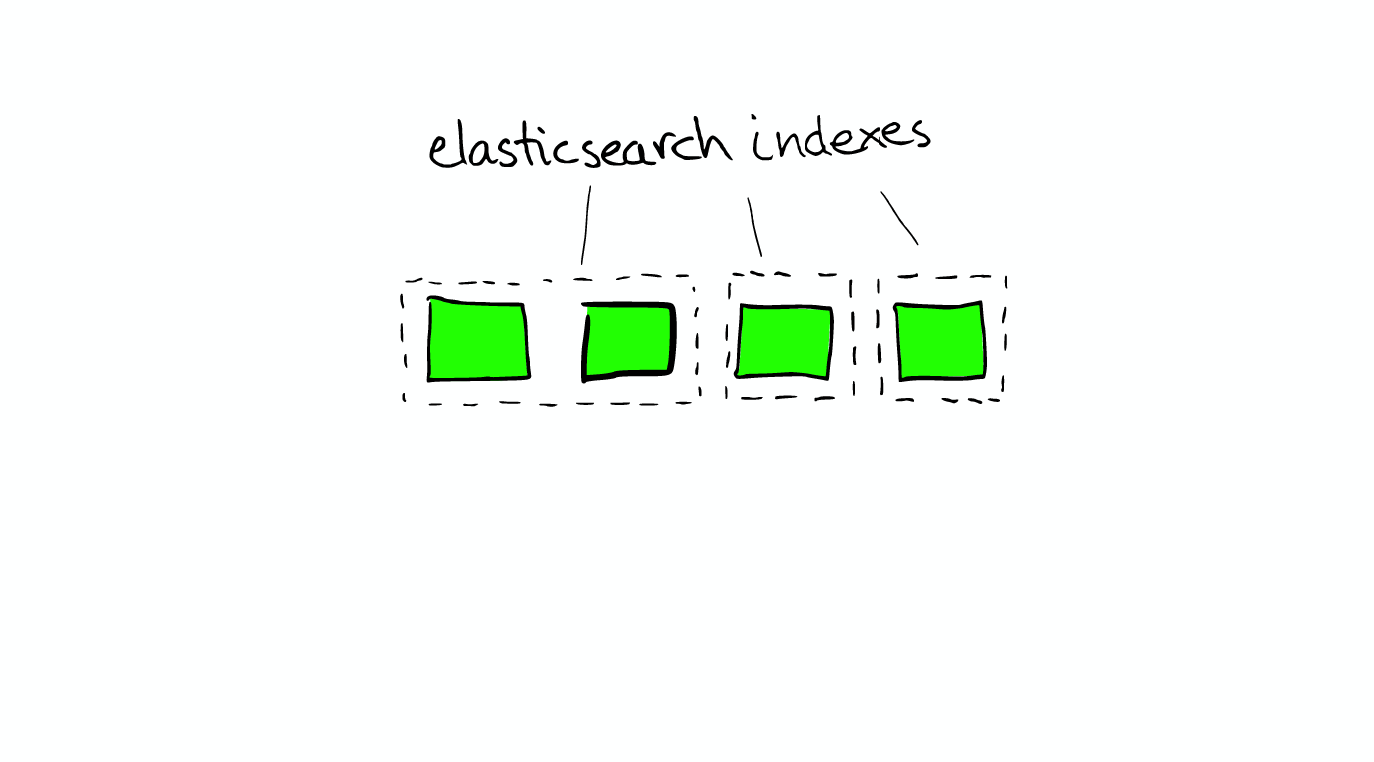
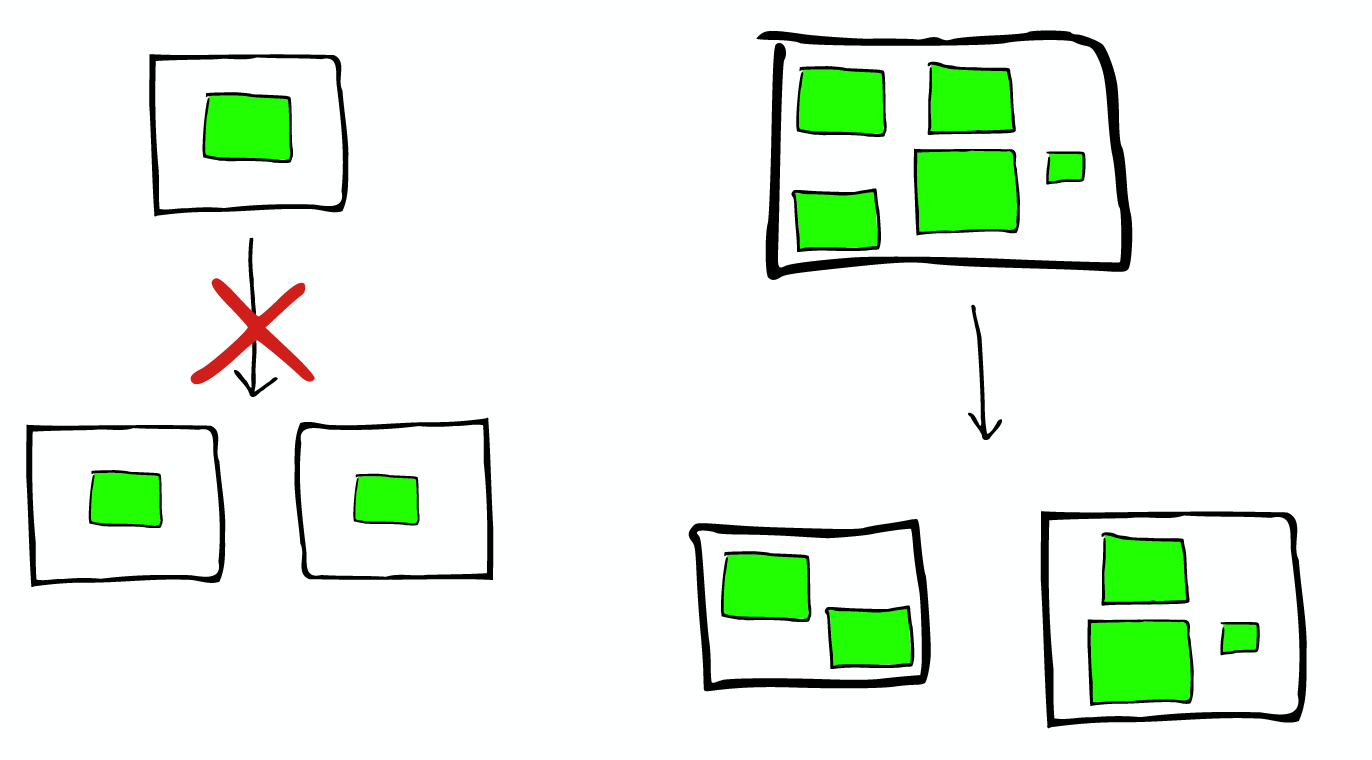
Index An index is a collection of documents [index是有相同特征的document的集合] that have somewhat similar characteristics. For example, you can have an index for customer data, another index for a product catalog, and yet another index for order data. An index is identified by a name (that must be all lowercase) and this name is used to refer to the index when performing indexing, search, update, and delete operations against the documents in it. In a single cluster, you can define as many indexes as you want.
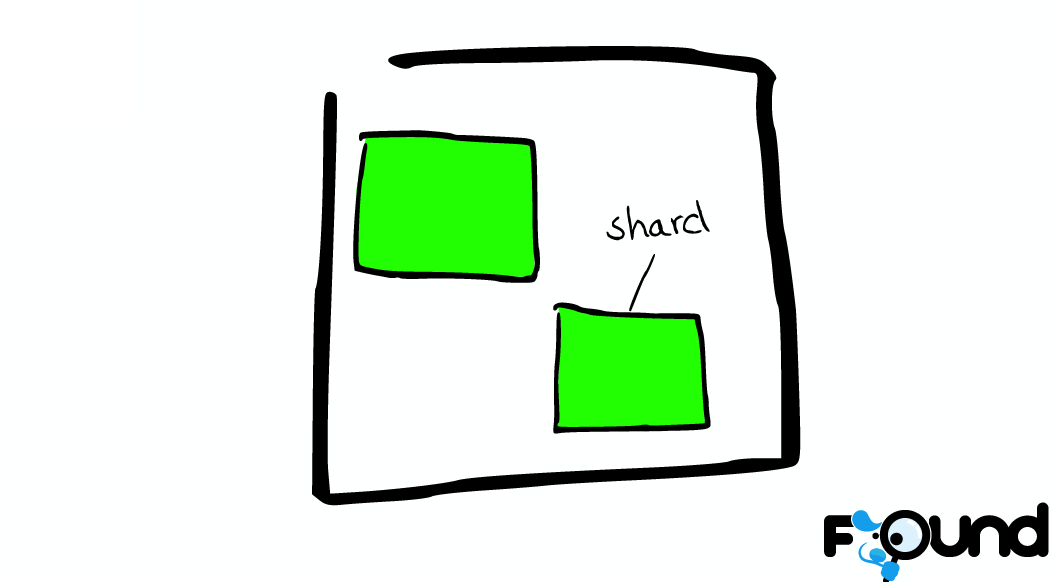
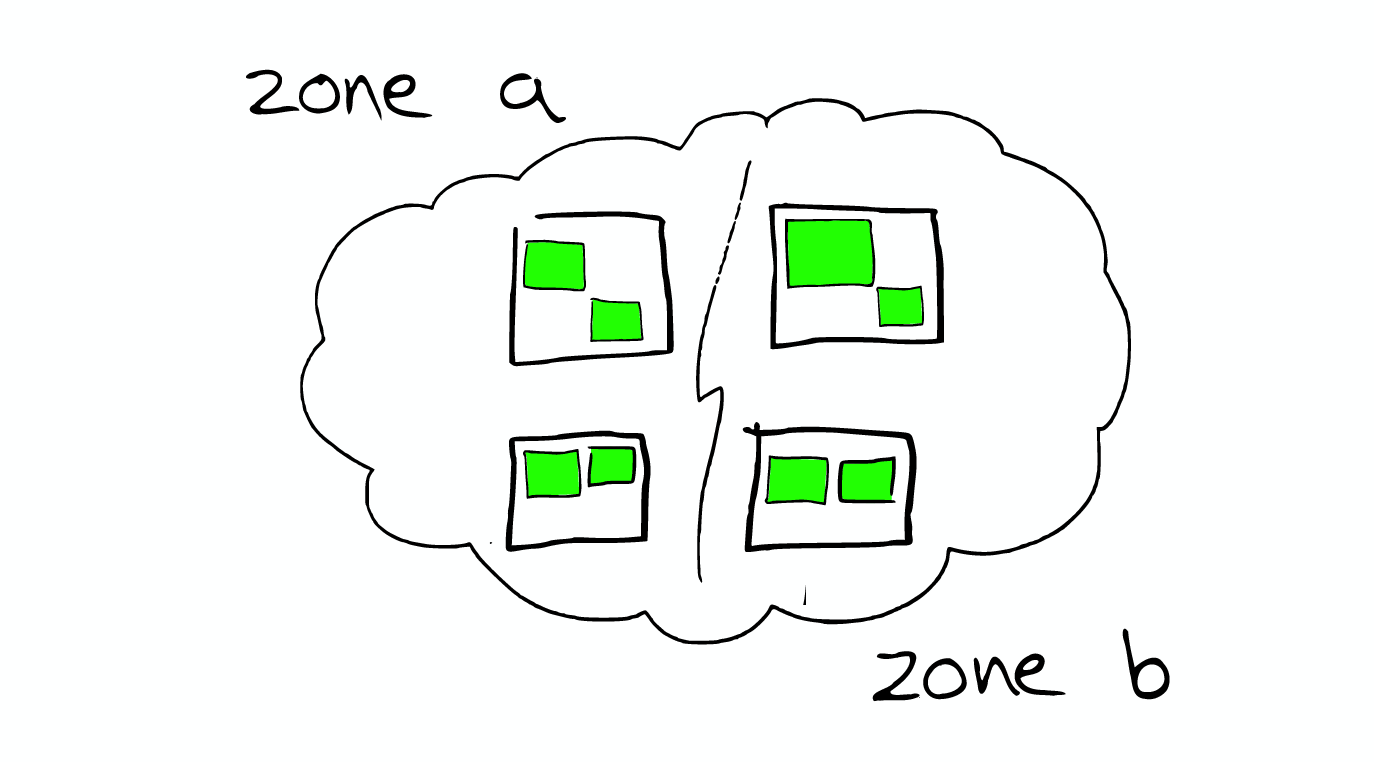
Type Within an index, you can define one or more types. A type is a logical category/partition of your index [type是index的一个逻辑分区] whose semantics is completely up to you. In general, a type is defined for documents that have a set of common fields. Document A document is a basic unit of information [document是能够被索引的信息的基本单元] that can be indexed. Within an index/type, you can store as many documents as you want. Shards & Replicas An index can potentially store a large amount of data. Elasticsearch provides the ability to subdivide your index into multiple pieces called shards. [elasticsearch可以把一个index分成多片,每片称为一个shard] When you create an index, you can simply define the number of shards that you want. Each shard is in itself a fully-functional and independent "index" that can be hosted on any node in the cluster. In a network/cloud environment where failures can be expected anytime, it is very useful and highly recommended to have a failover mechanism in case a shard/node somehow goes offline or disappears for whatever reason. To this end, Elasticsearch allows you to make one or more copies of your index's shards into what are called replica shards, or replicas for short. [elasticsearch允许保留shard的一个或多个副本,这个副本称为replica shard] It is important to note that a replica shard is never allocated on the same node as the original/primary shard that it was copied from. To summarize, each index can be split into multiple shards. An index can also be replicated zero (meaning no replicas) or more times. Once replicated, each index will have primary shards (the original shards that were replicated from) and replica shards (the copies of the primary shards). [备份index后,每个index会包含primary shards和replica shards] The number of shards and replicas can be defined per index at the time the index is created. After the index is created, you may change the number of replicas dynamically anytime but you cannot change the number shards after-the-fact.
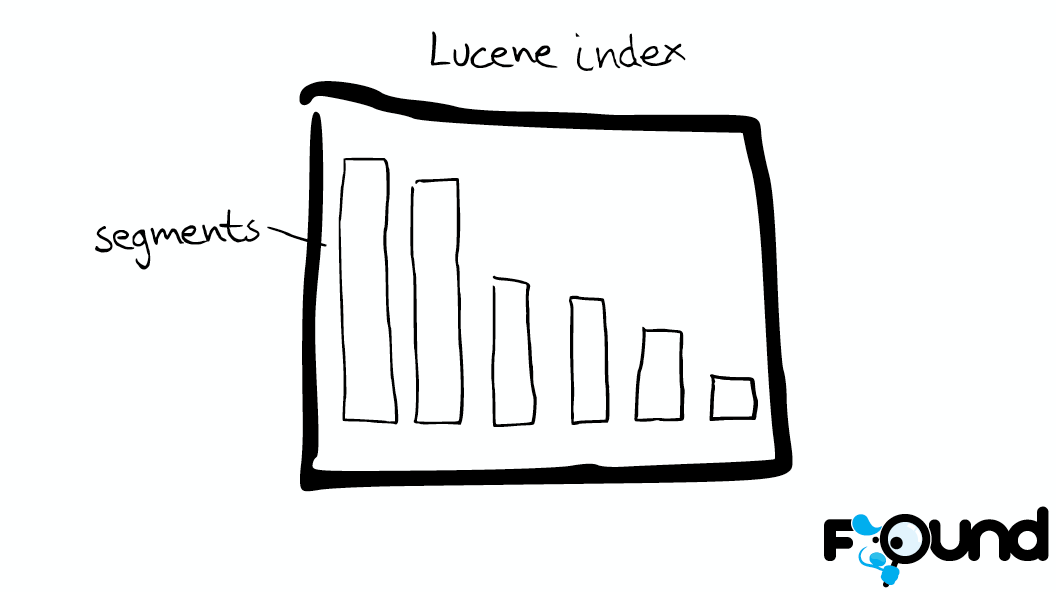
Shard=Lucene Index Each Elasticsearch shard is a Lucene index. There is a maximum number of documents you can have in a single Lucene index. Lucene is a Full Text search library. Within a lucene index, you have segments which is so like mini indexes.
Segment In within the Segment, we have see the data structure, like an inverted index, stored fields, document values, cache and so on.
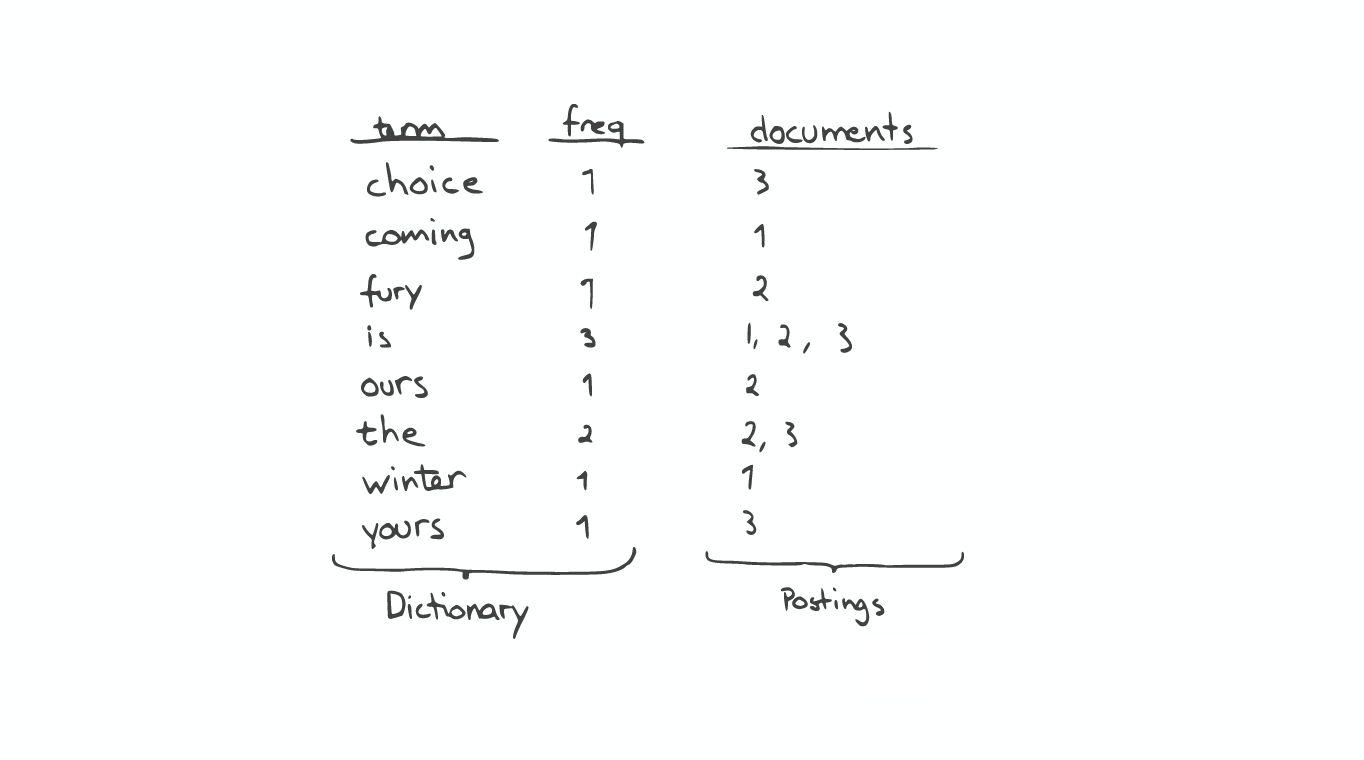
Inverted index The inverted index is the key data structure. It's consist of two parts: the sorted dictionary, which contains index terms. and for every terms you have a posting lists which is the document containing the term.
When you do a search, you first operate on the see the dictionary and then posting.
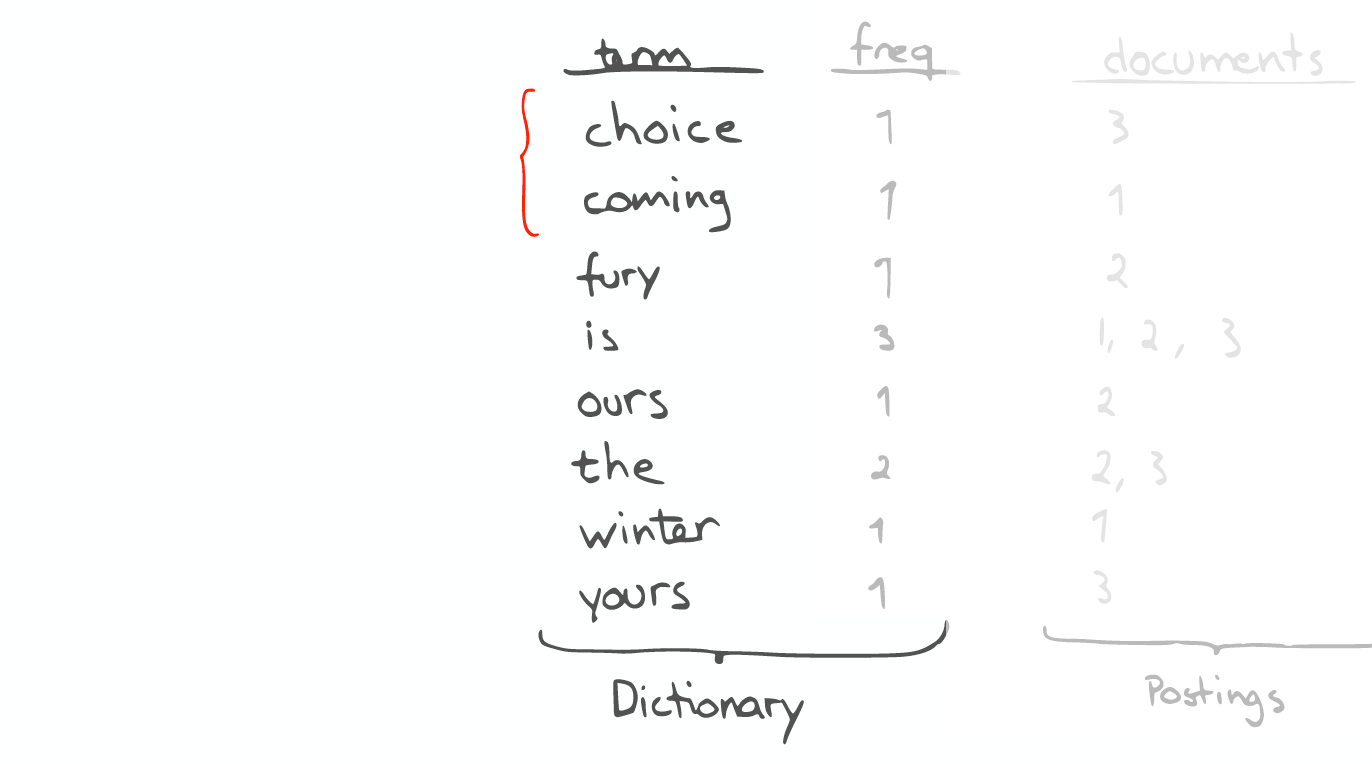
If you want to do a prefix search like in this case find everything starting with 'c', you can easily do so by a Binary Search in the dictionary.
But if you want to for example find every term contain the substring 'our', you have to go through every terms in the index, this is quite expensive.
Stored Field The Inverted Index is not very useful when you want look up the value given a doucment, like what the title for document No. 2. So to do that, there's other data structure like stored fields. Stored fields is a simple key-value store. By default, ElasticSearch will stores the entire JSON source.
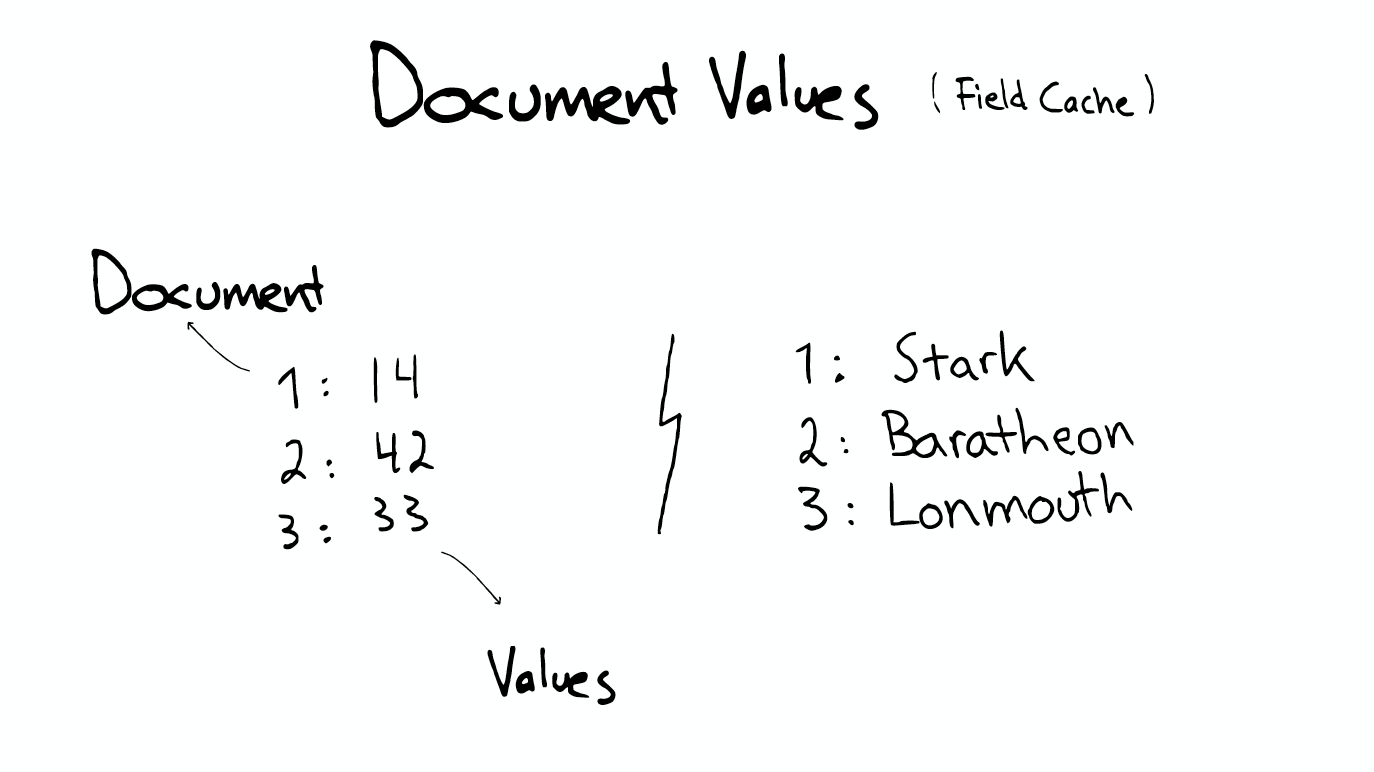
Document Values But even this, ElasticSearch is't very helpful when you need to read million of useful files. such as sort or facet or aggregation. Because it will be reading a lot of data that you don't need. There is another structure called document values which is essentially a column type storage, it's highly optimized storage structure with the same type of data. This is quite useful when you want to sort or aggregation. If you don't specify that you want this document values, ElasticSearch will use what called field cache which means that load all the values indexed into memory. It will be quite fast, but it used amount of memory. In short, these data structures Index Stored, Fields Document, Values Inverted and its cache, all in the segment.
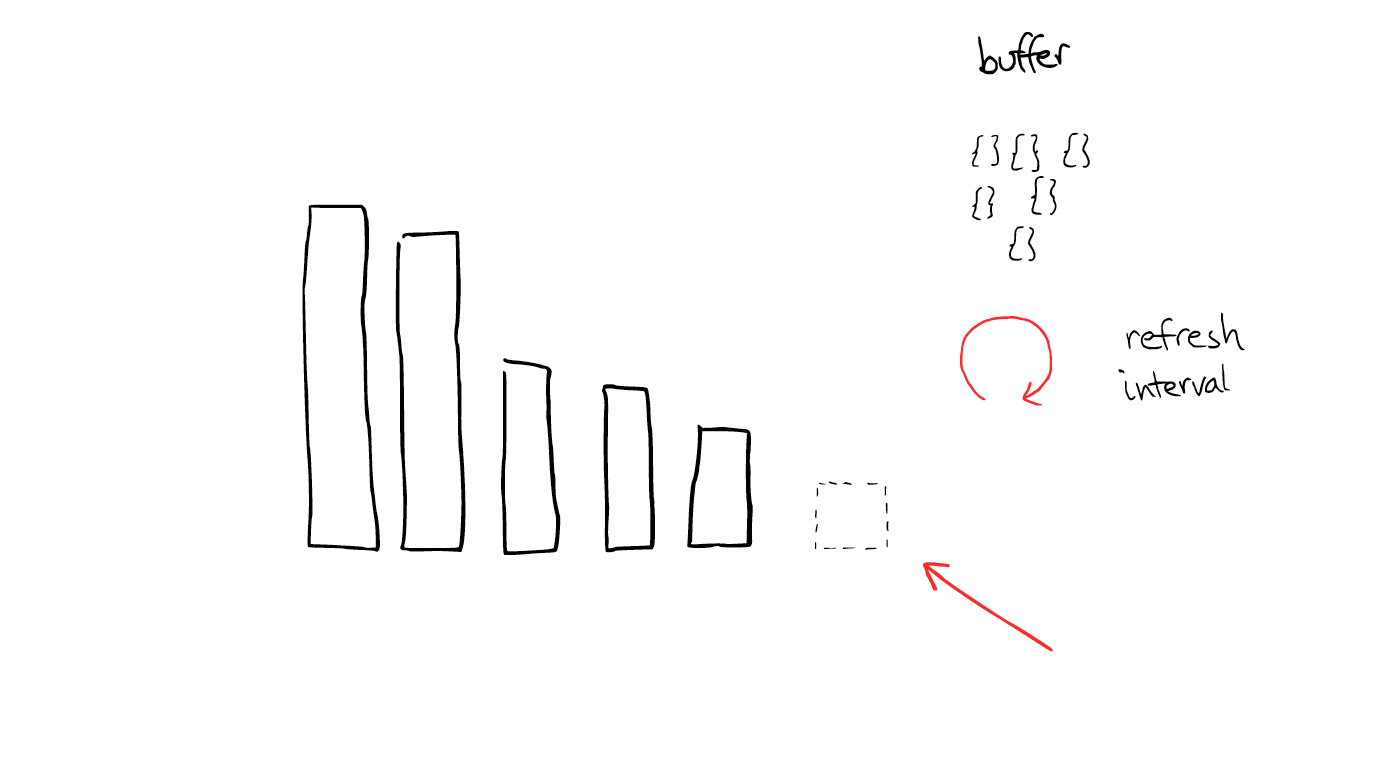
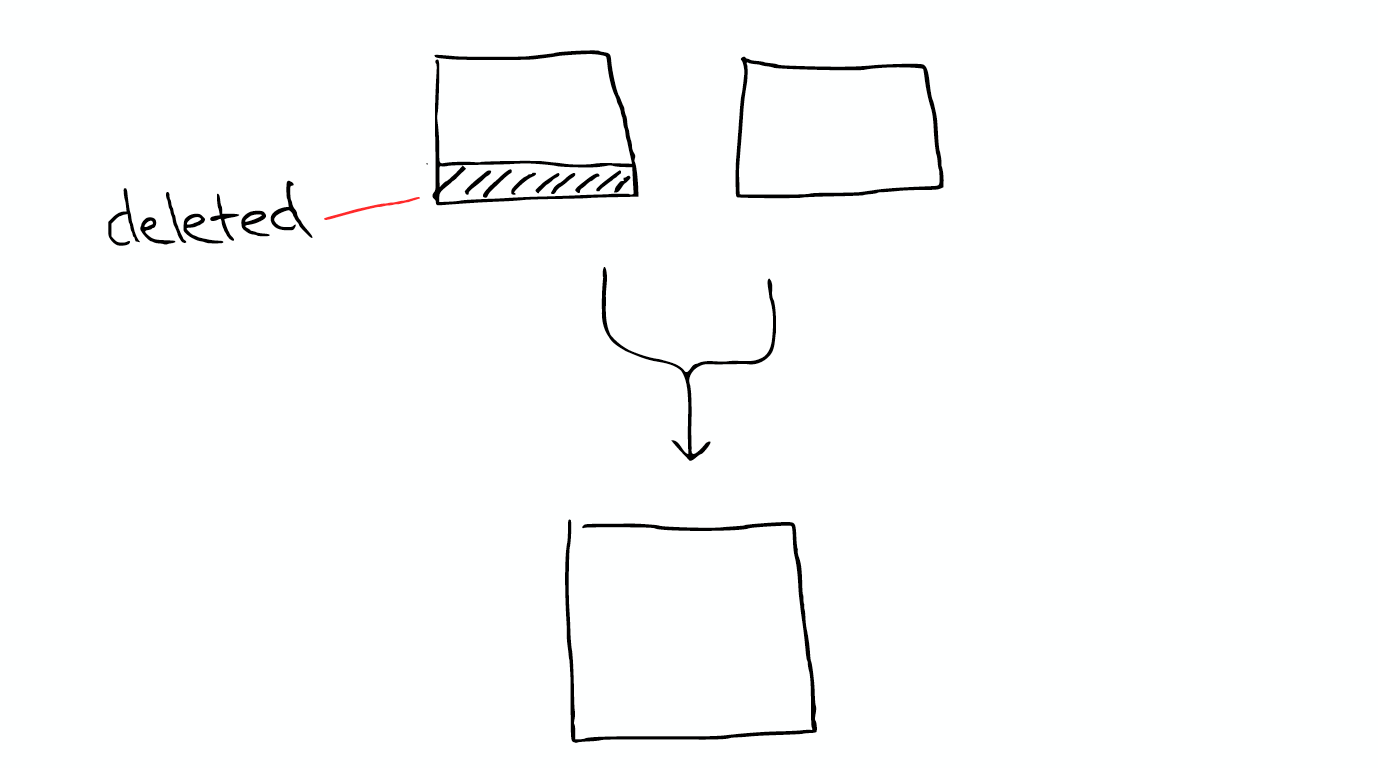
When lucene searching is occurs, it searches all the segment and merge the result. Segments are imutable: They never changed. This means for example when you delete a document, lucene just delete the location of the flag, but the file is still in its original plcace, will not change. When update, it's essentially first delete and then re-index. Compress all the things: Lucene is really good at compress. Cache all the things As you index new doument, ElasticSearch will buffer those document.and every refresh interval.
Over the time, you will get a lot of segments.
ElasticSearch will merge them together and during this process delete document are finally complete remove. So that's why adding document can costing the space into more smaller, it will cause merge, which may have more compression.
Search in Shard When you search these shards, it’s the same as search in segment. you search then more and then merge them together. But with the search in Segment Lucene is different, Shard may be distributed on different Node, so in the search and return results, all the information will be transmitted through the network.
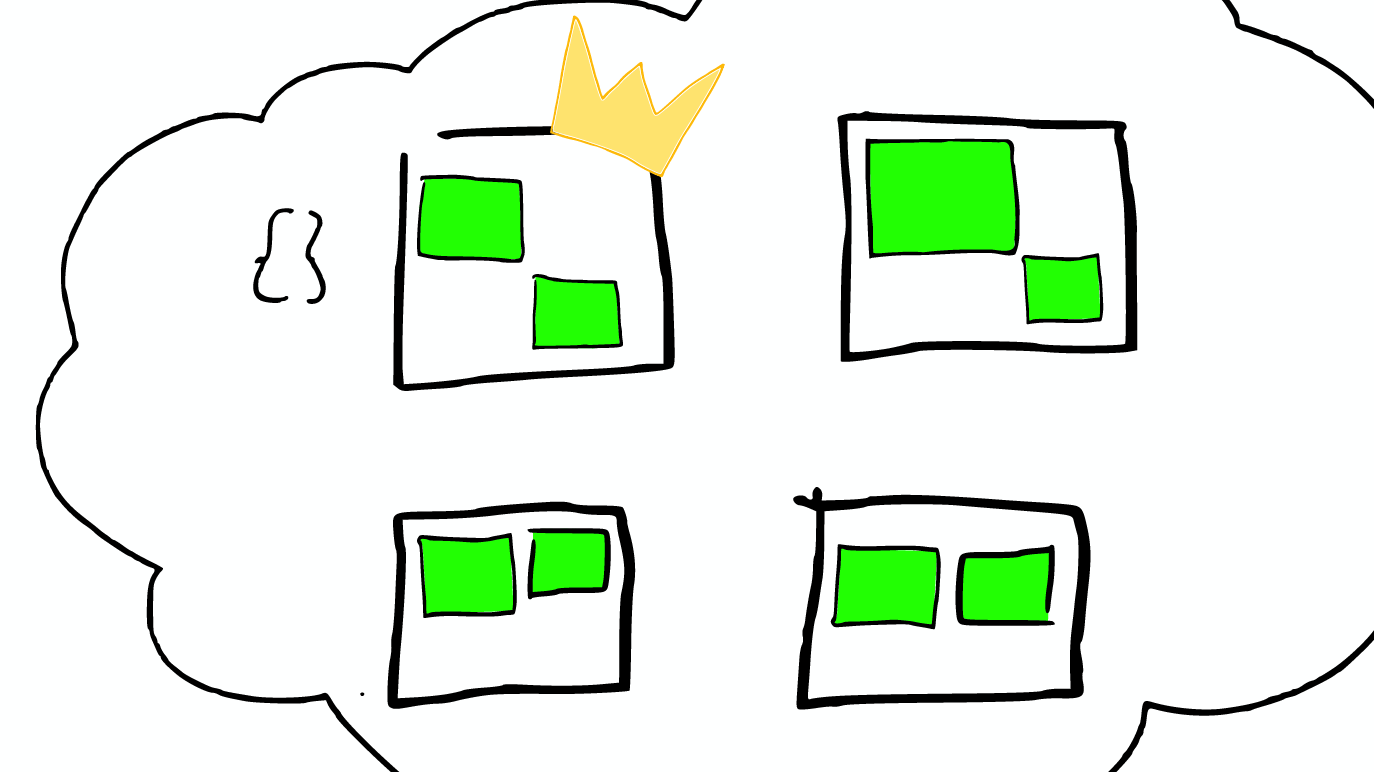
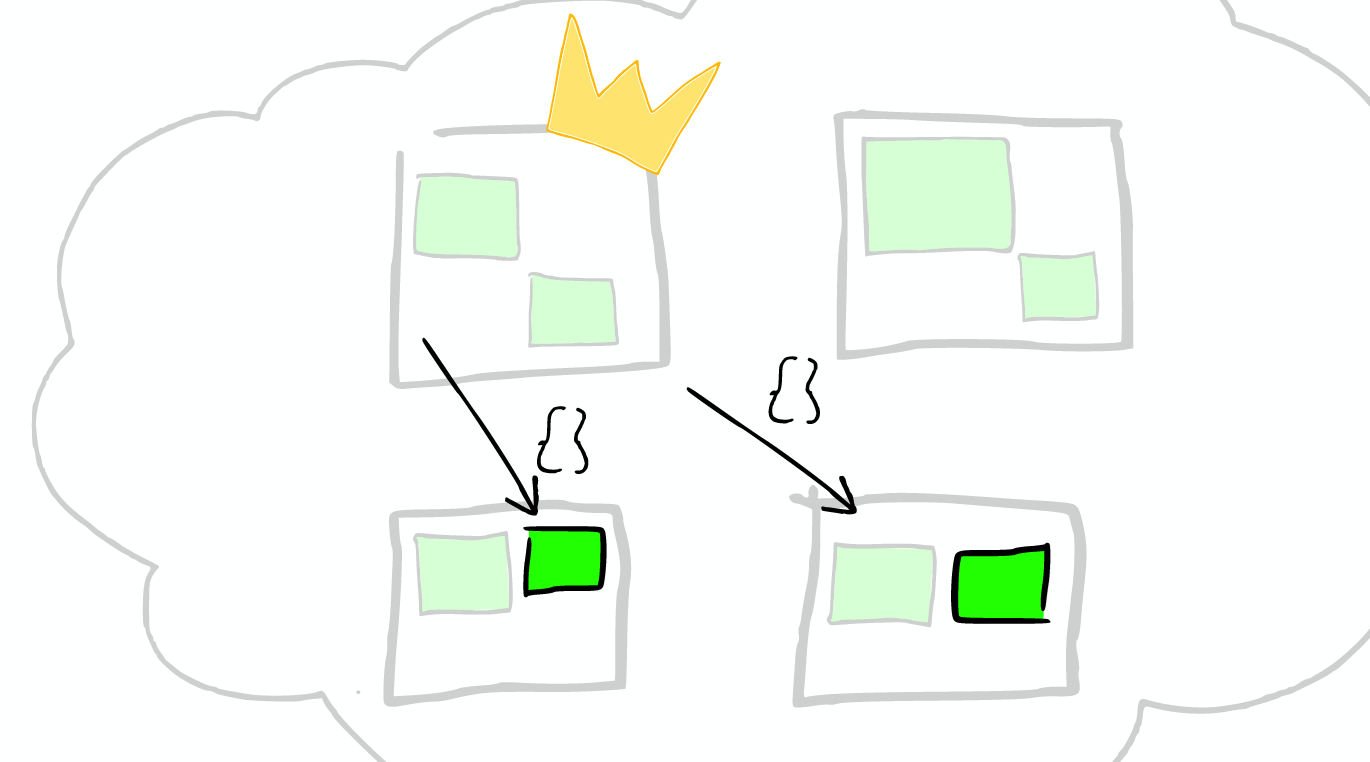
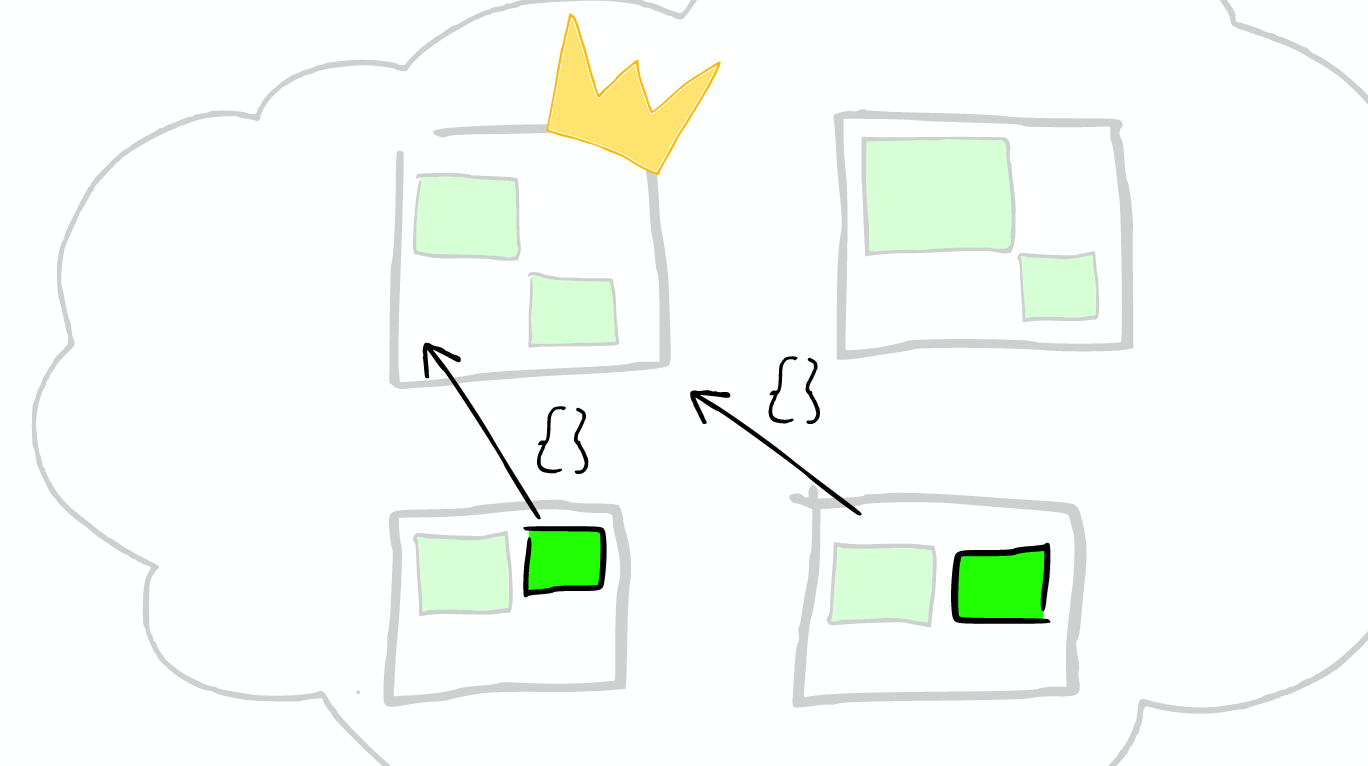
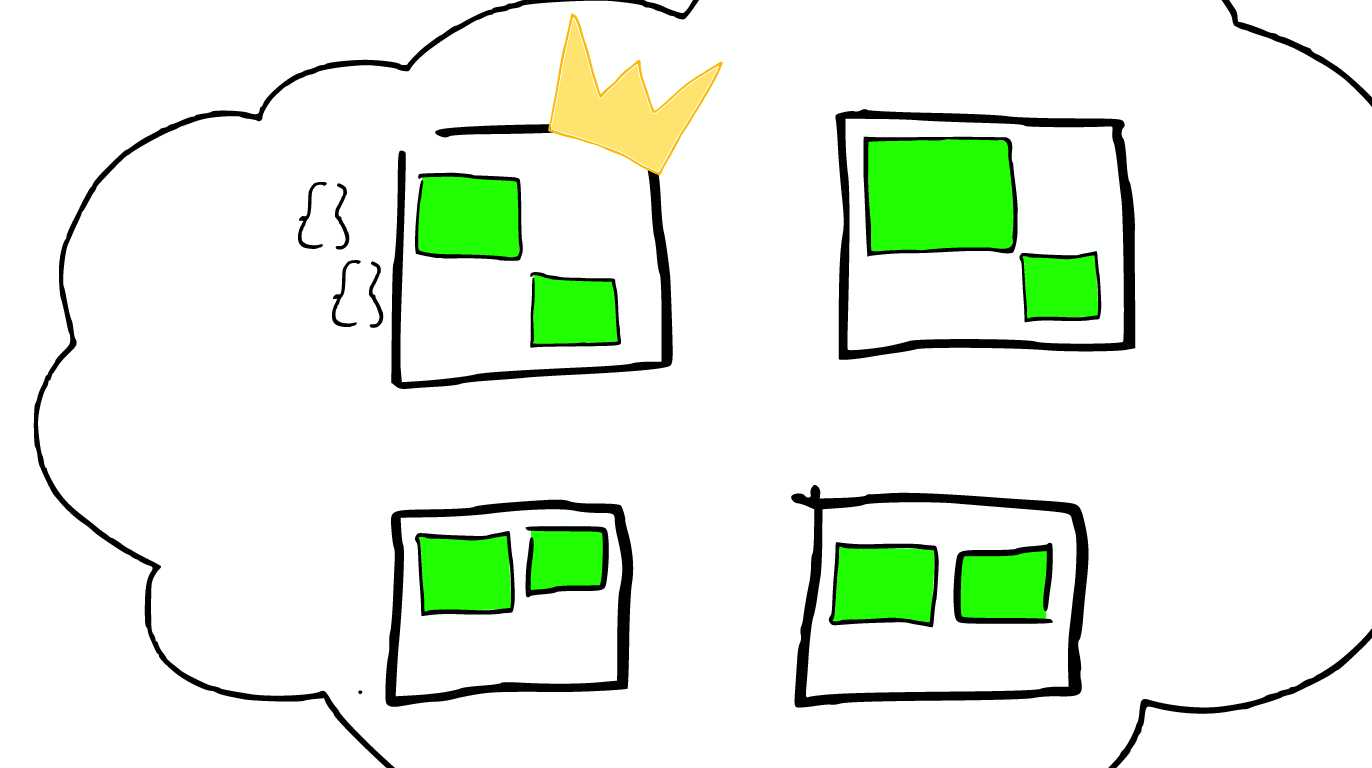
One key things to notice is that an ElasticSearch search index with two shards, searching one is essentially the same as searching two ElasticSearch in this search with one shards each. [1次搜索查找2个shard = 2次分别搜索shard]
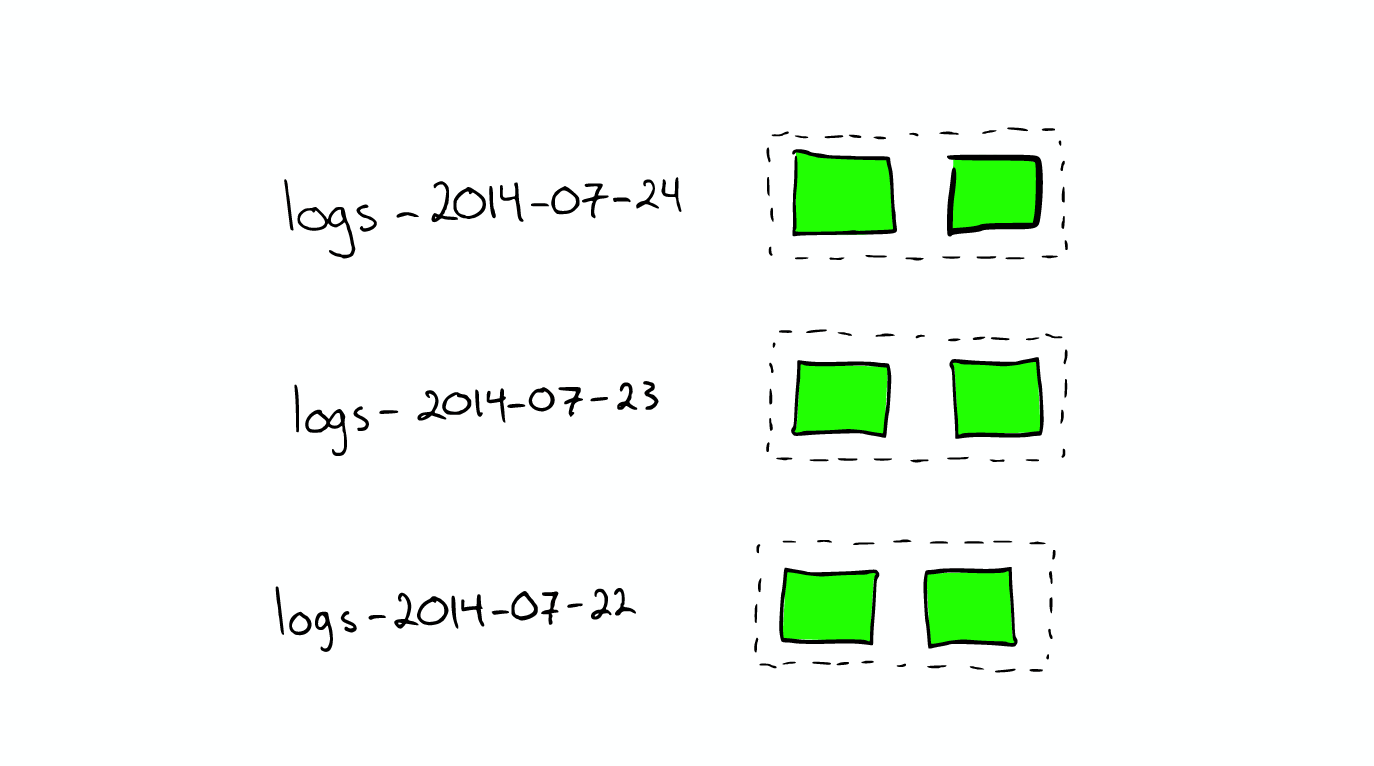
For the processing of log files When we want to search the log generated by a specific date, we can greatly improve the search efficiency by using the time stamp to block and index the log file. When we want to delete the old data is also very convenient, just delete the old index can be.
How scale Shard will not be split further, but shard may be transferred to different nodes.
Node allocation and Shard optimization * for the more important data index nodes, the better the performance of the machine * make sure that each shard has a copy of the information replica
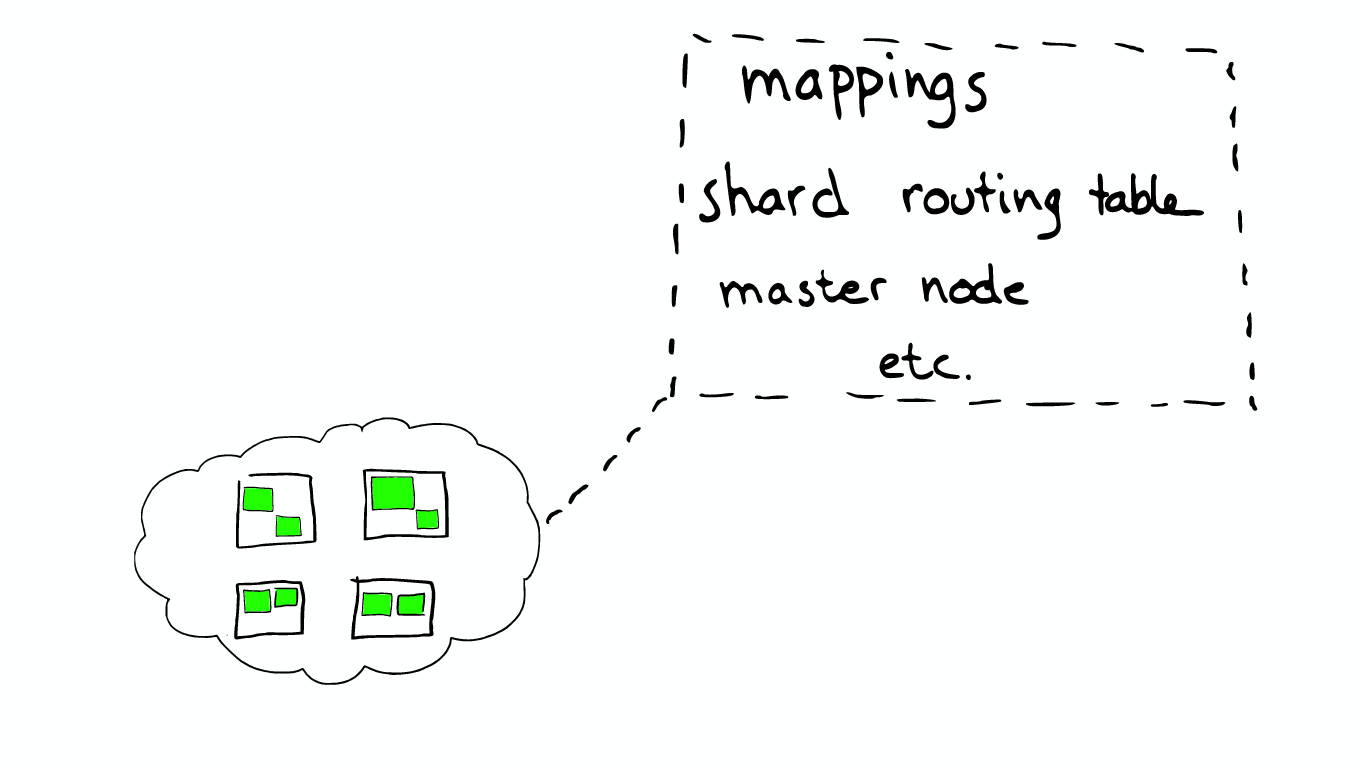
Routing Each node have a routing table, so when a request to any one node, ElasticSearch have the ability to forward requests to the desired node shard further processing.
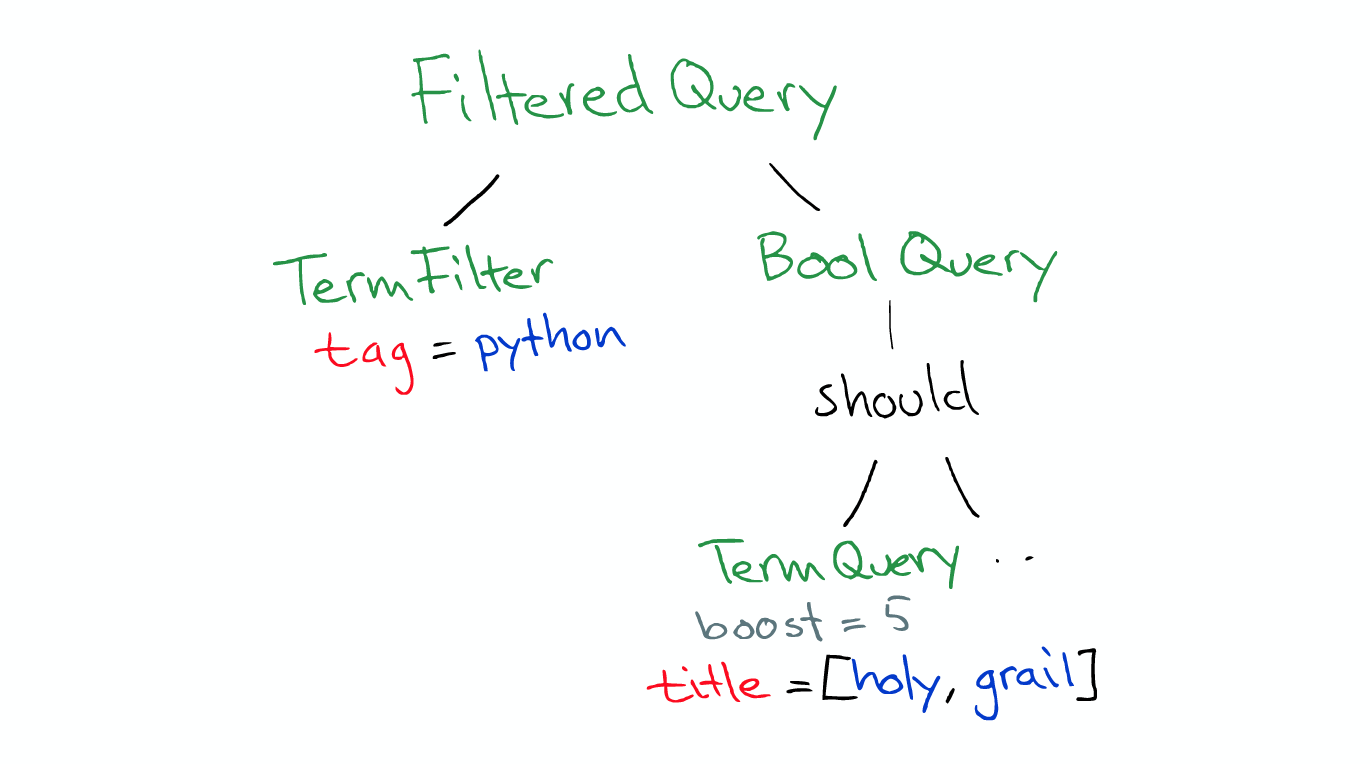
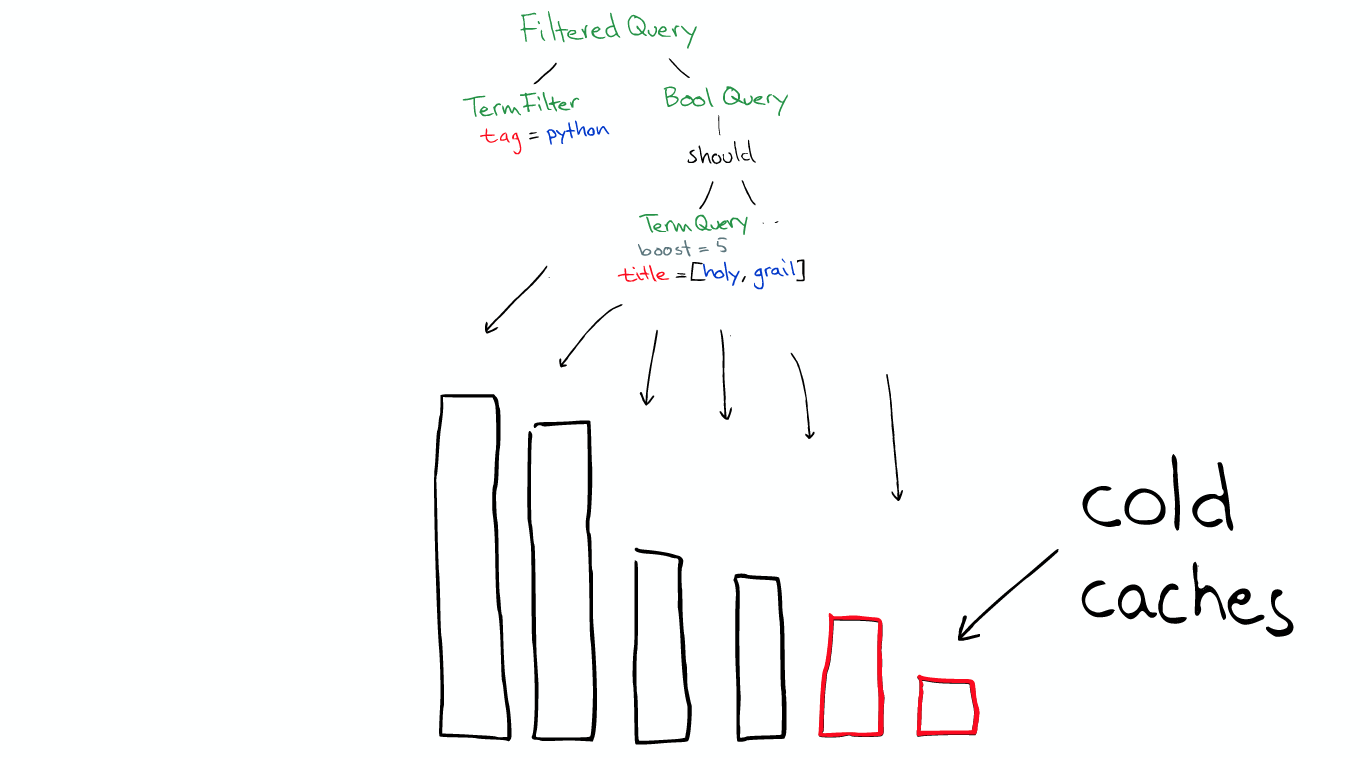
A Query Query is a type filtered, it has a term fiter, man a multi_match query. We also have an aggregations on authors, we want to top 10 authors, that's top 10 hits.
So this search request can be send to any node in your cluster.
That node becomes the coordinator node for the search request.
It was decided: * According to the index information, the request will be routed to which core node * Which copy is available * Wait
Before the real search ElasticSearch will convert the Query to Lucene Query.
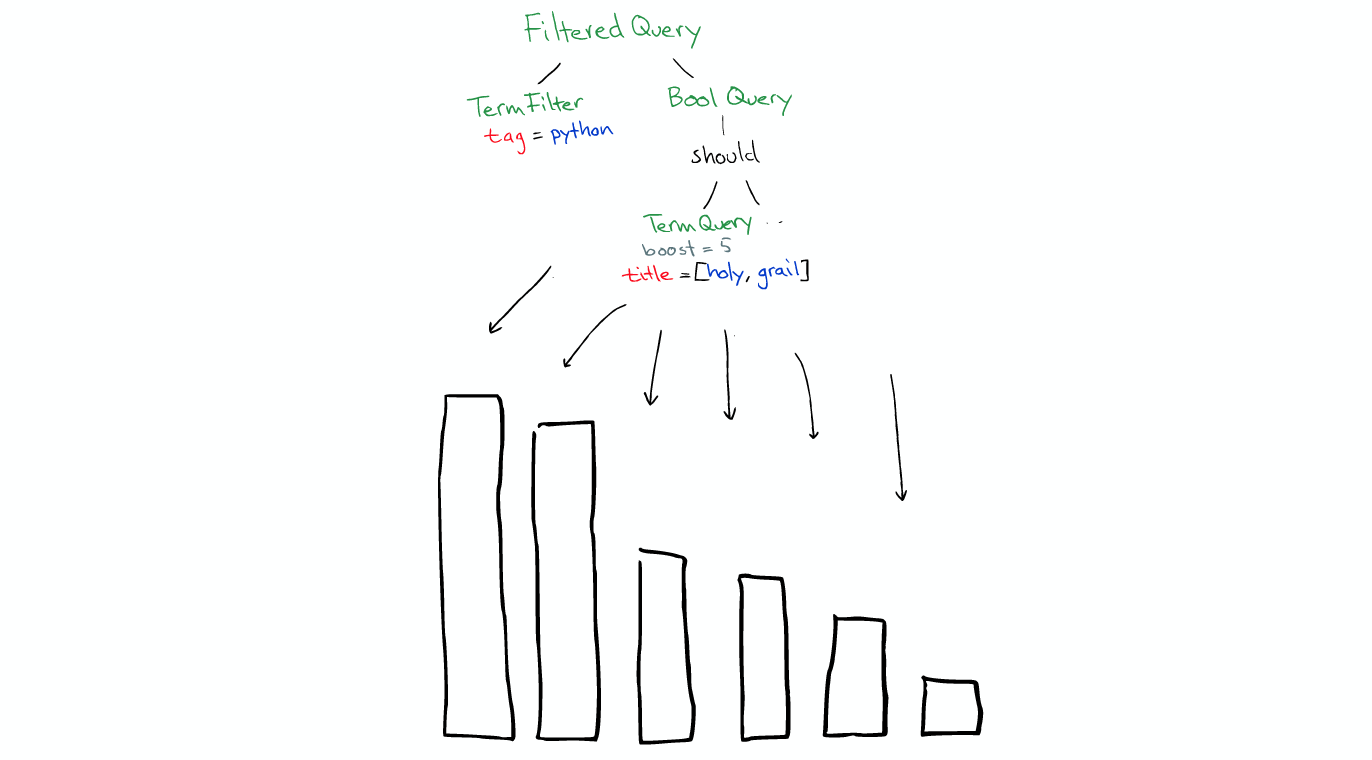
It will run all the segment.
The Filter condition itself also has a cache, when the filter and fields are already in the cache, using it is very fast.
But Query will not be cached, so if the same Query repeat, you need to do the application cache. [Query不会被缓存,所以如果相同的Query重复执行] * filters can be used at any time * Query is only used when you need score
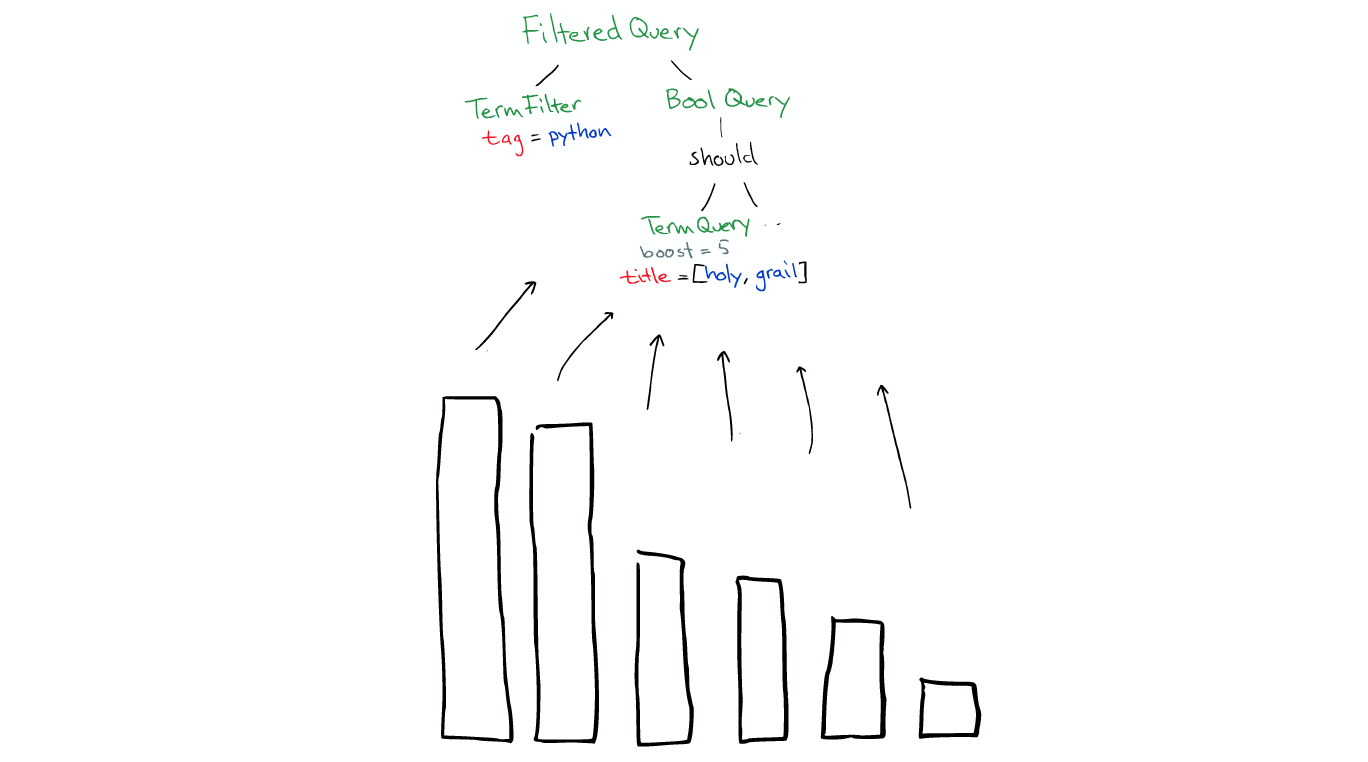
After the search is over, the results will be returned to the upper layer by layer.
The results get send back to the search coordinator.
By default, ElasticSearch will just ask for the id sorted documents for the top 10 hits. Because it doesn't really need all the document.
When the coordinator has all the data it merge it together. and send back it to users.
PPT: http://slides.com/vivisran/elasticsearch-from-the-bottom-up#/ Reference: http://www.cnblogs.com/richaaaard/p/5213569.html Video: https://www.youtube.com/watch?v=LDyxijDEqj4 转载请并标注: “本文转载自 linkedkeeper.com ” ©著作权归作者所有 |









6399
阅读数


视频课程

好文推荐